

Every day millions of people upload videos to Dropbox. Besides wanting their memories safe forever, they also want to be able to watch them at any time and on any device. The playout experience should feel instant, despite the fact that the content is actually stored remotely. Low latency playback of content poses interesting technical challenges because of the three main factors below.
1. Codec diversity
Most end users are familiar with extensions like .mp4, .avi, .flv, but not everybody is familiar with the fact that the file extension does not necessarily match the internal encoding of the content. People assume that an .mp4 file will certainly play on a Mac laptop, but that’s not always a safe assumption because the content might be encoded with some Microsoft/Google/Adobe/RealMedia specific codec (e.g. VC1/VP8). The video codec landscape has been very fragmented for at least 30 years now, and despite the efforts of MPEG to create open standards, the situation is still quite messy. The good news is that modern phones tend to produce mostly coherent content using H.264/AVC as codec and MPEG-4 container format, which indeed corresponds to the majority of the content we see in Dropbox.
2. Limited end-user network bandwidth
Users access their Dropbox content either via their home/office connection or via a mobile connection. Leaving mobile aside, even home connections are not as fast/reliable as most network providers advertise (see the ISP speed report from Netflix for some fun numbers), so bandwidth adaptation is a must to guarantee a fluid video playout.
3. Client capabilities
Different client devices impose different constraints, mostly due to the underlying hardware chipsets, both in terms of memory bandwidth and CPU power. For instance, the iPhone 3GS only supports baseline profile H.264/AVC.
The solution to these problems is to transcode (decode and re-encode) the source video to a target resolution/bit rate and codec that is suitable for a given client. At the beginning of the development of this feature, we entertained the idea to simply pre-transcode all the videos in Dropbox to all possible target devices. Soon enough we realized that this simple approach would be too expensive at our scale, so we decided to build a system that allows us to trigger a transcoding process only upon user request and cache the results for subsequent fetches. This on-demand approach:
- adapts to heterogeneous devices and network conditions,
- is relatively cheap (everything is relative at our scale),
- guarantees low latency startup time.
HTTP Live Streaming is your friend
#EXTM3U
#EXT-X-PLAYLIST-TYPE:VOD
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=150000
https://streaming.dropbox.com/stream/<access_token_layer_1>
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=500000
https://streaming.dropbox.com/stream/<access_token_layer_2>
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=1500000
https://streaming.dropbox.com/stream/<access_token_layer_3>
#EXT-X-ENDLIST
#EXT-X-VERSION:3
#EXT-X-PLAYLIST-TYPE:VOD
#EXT-X-TARGETDURATION:10
#EXTINF:10.0,
https://streaming.dropbox.com/stream/<access_token_layer_1_segment_1>
#EXTINF:10.0,
https://streaming.dropbox.com/stream/<access_token_layer_1_segment_2>
[...]
#EXTINF:10.0,
https://streaming.dropbox.com/stream/<access_token_layer_1_segment_N>
#EXT-X-ENDLIST
System overview
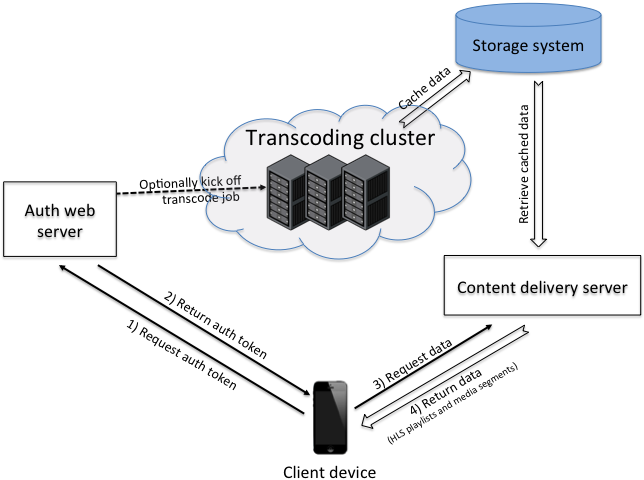
To begin streaming, a client application first issues a request to our web servers to obtain a temporary token (in the form of a URL) for the main HLS playlist. Since video playout typically happens on dedicated players that are not necessarily part of a client application, the token includes a one time password and expiration information that enables our servers to authenticate the external player before returning the content to it. The handler of this first request verifies if the content is already cached and, if that’s not the case, kicks off a transcoding job with different parameters based on client capabilities and network connection. Since H.264/AVC video transcoding is an extremely intensive operation and each transcoder machine can only perform a limited number of transcodes in parallel, it's important to pick the best worker at every request. The URL we return to the client also embeds information that allows us to route the request back to the transcoding worker, which is important to be able to serve the content while it’s being transcoded and before it’s cached in our backend.
Our worker clusters are implemented on Amazon AWS and consist of the following components:
- live transcoding servers are beefy cc2.8xlarge instances that can run several transcoding processes in parallel while still serving user’s requests. We have a hard limit on the number of concurrent transcodes on a given box and expose an application layer health check that allows us to temporarily take the machine out of service if the limit is exceeded. From our experience, each cc2.8xlarge machine can perform up to a dozen transcoding jobs in parallel before it will start falling behind.
- memcache is used for distributed coordination of the transcoding jobs. We use memcache to a) track progress of a job and b) report machine load. We use the load information to implement a good load balancing scheduler. This is crucial to prevent machines from getting overloaded.
- front end load balancer runs on cc1.xlarge instances and is powered by Nginx and HAProxy. We use Nginx for SSL termination and HAProxy to quickly take machines out of service when they are overloaded and fail the health check.
- persistent cache of transcoded material happens in a separate storage system. As always, storage is cheap compared to CPU so we store the results of the transcoding process for a certain amount of time to serve them back in subsequent requests. We maintain references to cached data in our internal databases so we can implement different retention policies based on users’ usage patterns.
Preparing, encoding and segmenting
We use ffmpeg for the actual transcoding because it supports most formats. Our pipeline implements the following three steps.
1) prepare the stream for cooking
Since we want to stream data as we transcode it, we need to rearrange the input stream in a way that is suitable for piping it into ffmpeg. Many people refer to this process as “fast-starting” the video, and there are a few tools available on the internet that can help you get started. Ultimately, we wrote our own solution in python to allow us to debug issues and profile performance. In practice fast-starting for mp4 consists of extracting the "moov atom," which contains most of the video's metadata, rearranging it to the beginning of the file, and then adjusting the internal offsets to the data accordingly. This allows ffmpeg to immediately find the information about resolution, duration and location of data atoms and start the transcoding as the data is fed into it.
2) re-encode the stream
The command line for ffmpeg looks something like the following:
ffmpeg -i pipe:0 -dn -vcodec libx264 -vsync 1 -pix_fmt yuv420p -ac 2
-profile:v baseline -level 30 -x264opts bitrate=<rate>:vbv-maxrate=<rate>
-rc-lookahead 0 -r <fps> -g <fps> -refs 1 -acodec libfaac -async 1
-ar 44100 -ab 64k -f mpegts -s <target_resolution> -muxdelay 0 pipe:1
We use H.264/AVC baseline profile level 3.0 to guarantee compatibility with all devices including iPhone 3GS (we are planning to improve on that in the near future). Some of the parameters are the result of us trading off a bit of quality to minimize the startup time for live transcoding. Specifically, we found that reducing the value of muxdelay, having only one reference frame and disabling scenecut detection all contributed in reducing the latency introduced by ffmpeg. The output container format is MPEG transport as required by HLS.
3) Segment the transcoded output
The output of ffmpeg is segmented with a C++ tool we developed internally on top of libavcodec. Apple provides a segmenter tool but we decided to not use it because it runs only on Mac (we are linux friends like most readers here) and does not natively support pipelining. Also, recent versions of ffmpeg (we use 2.0) come with a segmenter tool, but we found it introduces significant latency to our pipeline. In summary, the reasons why we ended up writing our own tool were because it allows us to 1) optimize end-to-end latency, 2) guarantee the presence and the positioning of IDR (Instantaneous Decoder Refresh) frames in every segment and 3) customize the length of the segments we generate.
The last point is particularly important because the length of the video segment is directly proportional to the transmission time from the server to the client on a bandwidth constrained channel. On one hand, we want very short segments to lower the transmission time of each of them but on the other hand we’d like to minimize the number of in-flight requests and the overhead per request due to the roundtrip latency between the client and the server. Since we are optimizing for startup latency, we begin with smaller segments and then ramp up to longer ones to diminish request overhead, up to the target segment length of 5 seconds per segment. Specifically, the length for the very first segments looks something like 2s, 2s, 3s, 3s, 4s, 4s, 5s, …. We picked these values because a) the standard poses some restrictions on how fast we can increase the length of consecutive segments (this is to avoid possible underflows) and Android does not allow for fractional segment lengths (those were introduced in version 3 of the HLS standard).
Lowering startup time by pre-transcoding

Still, that is not sufficient to provide the “feel instant” experience we wanted for our users so we revisited the idea of pre-transcoding some of the material and we decided to process only the first few seconds of every video. The pre-transcoding cluster is independent of the live transcoding one to not affect the performance of live traffic and is hooked up with a pipeline that is triggered on every file upload. The first few seconds of every video are processed and stored in our cache, and the remaining part is generated on demand whenever the user requests. This approach allows us to transmit to the client the first segments very quickly while the transcoder starts up and seeks to the desired offset. We retain references to all processed material so we can easily implement different retention policies as needed.
Recap
- pre-transcoding everything would be nice and makes things much easier to implement, however it’s too expensive at our scale.
- fast-starting is required to handle video files generated by mobile devices if you want the transcoder to progress while you feed data into it.
- HLS is a great solution to enable streaming over heterogeneous networks/devices and allows for flexible and creative solutions in the way you structure your output.
- load balancing is not to be underestimated. It’s a tricky problem and can easily trash your system if done wrong.
- experimenting with ffmpeg parameters lets you explore the tradeoff between quality and latency that is appropriate for your application.


