

Introduction
Most representations of data contain a lot of redundancy, which provides an opportunity for greater communication efficiency by compressing the content. Compression is either built-in into the data format — like in the case of images, fonts, and videos — or provided by the transportation medium, e.g. the HTTP protocol has the Accept-Encoding / Content-Encoding header pair that allows clients and servers to agree on a preferred compression method. In practice though, most servers today only support gzip.
In this blog post, we are going to share our experiences with rolling out Brotli encoding for static content used by dropbox.com, decreasing the size of our static assets by 20% on average. Brotli is a modern lossless compression algorithm based on the same foundations as gzip (LZ77 and Huffman encoding), but improves them with a static dictionary, larger matching windows, and extended context modeling for better compression ratios. We won’t go into much detail on how Brotli works here; if you want to dig deeper into the compression format, you can read a great introduction to Brotli internals by Cloudflare.
Why Brotli
Before starting any project, we need to ask ourselves whether it is worth the engineering resources involved. In this phase, it also makes sense to investigate alternatives. Here are the two most obvious ones for this project:
- Improve gzip compression: LZ77 and Huffman encoding can go a long way (after all Brotli itself is using them under the hood) but there are some architectural limitations that can’t be worked around. For example, the maximum window size is limited by 32kB. Later we’ll discuss how to squeeze an additional 5-10% from the venerable deflate by using pre-compression, alternative libraries, and sometimes even data restructuring, but Brotli does even better.
- Use Shared Dictionary Compression: This approach was once taken by one of our engineers, Dzmitry Markovich, while he was at LinkedIn, but it has a number of downsides:
- Even though this compression method has been around since 2008 it still lacks support in browsers. You can try comparing the “support matrices” of SDCH and Brotli; basically the former is only supported in Chrome-based browsers. Most server-side setups also lack support for SDCH.
- SDCH requires an additional static-build step to periodically update dictionaries. This will become especially complex when one needs to enable SDCH for dynamic, localized content.
Limiting scope
We’ll only focus on static resources for now, and skip all of the on-the-fly/online/dynamic data compression. This gives us the following benefits:
- Compression times do not matter (within reasonable bounds). We can always compress data with the highest possible compression settings.
- The size of the data is always known in advance. That way additional optimizations can be applied, like compression window tuning. Also we can use algorithms that do not support streaming.
- We can perform a compression-decompression round-trip, verifying that compression did not corrupt any data. This is especially useful if we are going to use less stable compression libraries (but still useful even for something as well tested as zlib).
Deployment
The main problem with rolling out new compression algorithms for the Web is that there are multiple dependencies besides the server itself: in particular, web browsers and all the agents in the middle need to support it, such as Content Delivery Networks (CDNs) and proxies. Let’s go over all of these components one-by-one.
Serving pre-compressed files
Webservers responsible for static content usually spend their time in a repeating loop consisting of the following elements:
- read data
- compress it
- send compressed data to client
- discard compressed data, freeing memory
To prevent repeated compression steps for static content, nginx has a builtin gzip_static module, which will first try looking for pre-compressed versions of files and serve them instead of wasting CPU cycles on compression of the original data. As an additional optimization, it is also possible to only store compressed versions of the files by combining gzip_static with a gunzip module to save space on disk and in the page cache. Also, decompression is usually orders of magnitude faster than compression, so the CPU hit is almost non-existent. But let’s get back to Brotli. Piotr Sikora, well known to subscribers of nginx-devel mailing list, has written an ngx_brotli module that adds support for Brotli encoding to nginx, along with brotli_static directive that enables serving of pre-compressed .br files. This solves the server-side requirements.
Brotli pre-compression
The biggest chunk of the actual work was adding a step to our static build pipeline that processes all the compressible MIME-types inside our static package and emits brotli-encoded versions of them.
Brotli sources provide C, Java, and Python bindings. You can either use these bindings or just fork/exec the bro tool to directly compress files. The only caveat at this point is to balance the Brotli window size. Bigger compression windows lead to higher compression ratios but also have higher memory requirements during both compression and decompression, so if you are pre-compressing data for mobile devices, you may want to limit your window size.
It is worth noting that there is no reason to set the compression window higher than the source file size. The window size in Brotli is specified in bits, from which the actual size is calculated via: win_size = (1 << wbits) - 16, so you need to take these 16 bytes into an account when computing your window size.
The allowed range of window sizes is currently [1KB, 16MB], though there are some talks about using brotli with large windows (up to 1GB).
GZip pre-compression
As an alternative to Brotli, you could try to optimize gzip for pre-compression. There is not much difference in compression ratios for zlib levels higher than 6, so pre-compression with gzip -9 on average gives less than 1% improvement over our default gzip -6. But zlib is not the only implementation of the deflate format; luckily there are alternatives that offer various benefits:
- zlib-ng, intel-optimized zlib fork, and cloudflare zlib fork. These are mostly aimed at better compression speeds on modern x86_64 hardware and are generally compiled into web servers to do CPU-efficient on-the-fly compression. But since they give almost no benefit to compression ratios they do not fit our pre-compression use-case.
- Zopfli-based compressors spend an order of magnitude more time and produce almost optimal deflate-compatible results, yielding 3-10% of improvement over zlib.
- Libdeflate gives comparable compression ratios to Zopfli at a fraction of CPU time, but all of that comes at the cost of lacking any kind of streaming interfaces. This looks like a perfect candidate for our pre-compression case.
- 7-Zip also has deflate-compatible mode, but it performs slightly worse than libdeflate on our dataset.
Content Delivery Networks (CDNs)
In theory, CDNs should support Brotli transparently, the same way they currently do with gzip: if the origin properly sets the Vary: Accept-Encoding header. In practice, though, CDNs are heavily optimized for the gzip/non-gzip use-case. For example:
- CDNs can normalize clients’
Accept-Encodingtogzipwhen passing a request to the origin, store compressed version of the response in cache, and decompress data on-the-fly for clients that do not support gzip. This “optimization” can be easily spotted by collecting a distribution ofAccept-Encodingvalues on your origin: if all the requests hitting your origin haveAccept-Encodingset togzipthen your CDN most likely “normalizes” this header. - Some CDNs ignore the value of the
Varyheader unless you explicitly ask them not to. This can potentially lead toContent-Encoding: brresponses being cached and handed off to clients that do not support Brotli, regardless of theirAccept-Encoding. This misbehavior is very dangerous, but can be trivially tested with a series ofcurl‘s: theContent-Encodingof a cache hit response should depend on the request’sAccept-Encoding.
(By the way, if you are not familiar with Vary header, you probably want to read Fastly’s blog post about best practices of using Vary.)
If you are going to add the Accept-Encoding header to your cache key, you should also be aware of all the downsides: values of that header are very diverse, and therefore your CDN cache hit rate will go down. Judging by the data provided by Fastly, Accept-Encoding has a really long tail of values, and so a naive implementation of a cache key may not always work. The solution here is to normalize the header before it is passed to the upstream. You can use this code as a reference example.
Intermediaries
Browser support
Client side support is, fortunately, the least problematic of all. Brotli was developed by Google and hence Chrome has supported it for quite a while. Since Brotli is an open standard, other browsers have support for it as well:
- Firefox since the last Extended Support Release (ESR), v45
- Microsoft Edge will have support for it on the next version, v15.
The only straggler is Safari, which does not advertise Brotli support even in the latest Technological Preview.
We did run into an unexpected issue with very old versions of Firefox 45 ESR (e.g. 45.0.*). Even though it advertises Brotli support, it couldn’t decode some files. Further digging revealed that it can’t unpack files encoded with windows smaller than original file size. As a workaround, you can either increase your window size or, if you are using nginx, implement the brotli_disable directive, which will mirror the gzip_disable behavior, but with a blacklist for brotli-misbehaving browsers.
Results
Enabling Brotli decreased the size of the payload fetched by users from CDN on average by 20%! Pretty pictures follow.
(Oh, speaking of which, in case you’re wondering why all the graphs are in xkcd style: no reason really, it’s just fun. If your eyes bleed from the Comi^WHumorSans typeface there are links to “boring” SVGs at the bottom.)
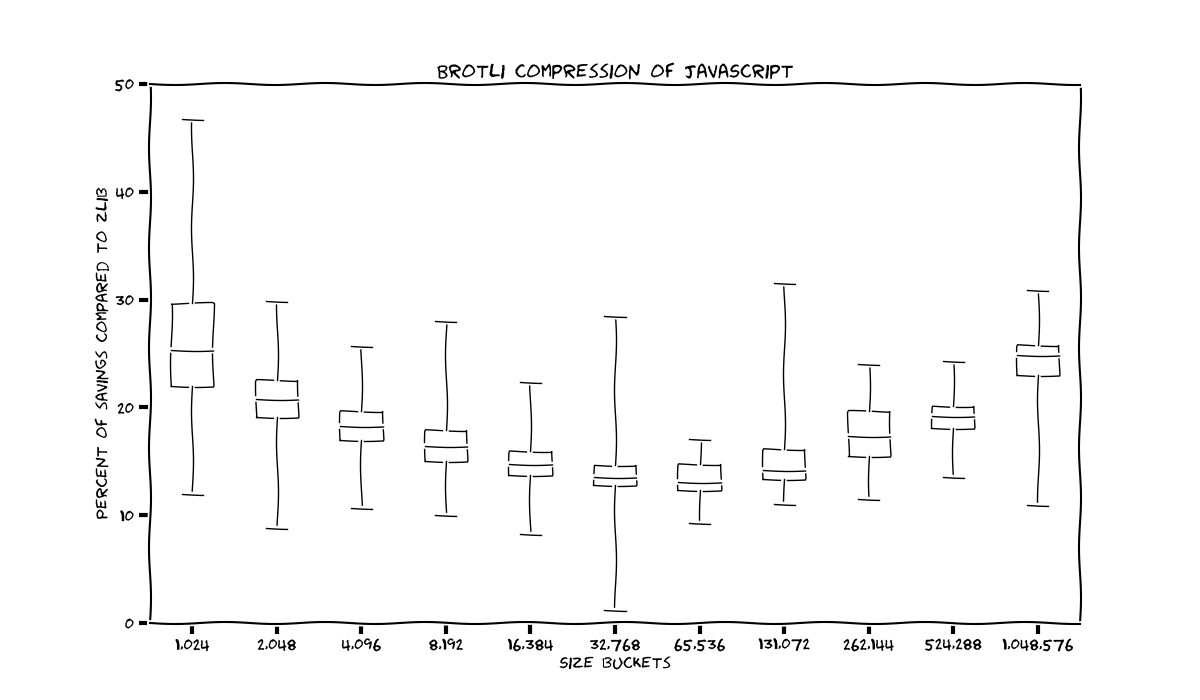
A small note about how to read the graphs. We’ve split all our static assets by type, divided each group into logarithmic size buckets from 32 bytes to 1MB, and then computed the average compression ratio win over gzip -9 for libdeflate and Brotli, respectively. Error bars represent the 95% confidence interval. For those of you who like to get all sciencey and stuff, boxplots are also attached (for the Brotli part of the dataset only) with IQR, median, min, and max stats.
JavaScript
Let’s start with normal (unminified) JavaScript files. The results here are good; Brotli gives an astonishing 20-25% of improvement over zlib on both small files (where its static dictionary has a clear advantage), and on huge files (where now a bigger window size allows it to beat gzip quite easily). On medium-sized files Brotli “only” gives 13-17% of improvement.
Libdeflate also looks quite good: getting additional 4-5% out of gzip is a low-hanging fruit that anyone can take advantage of.
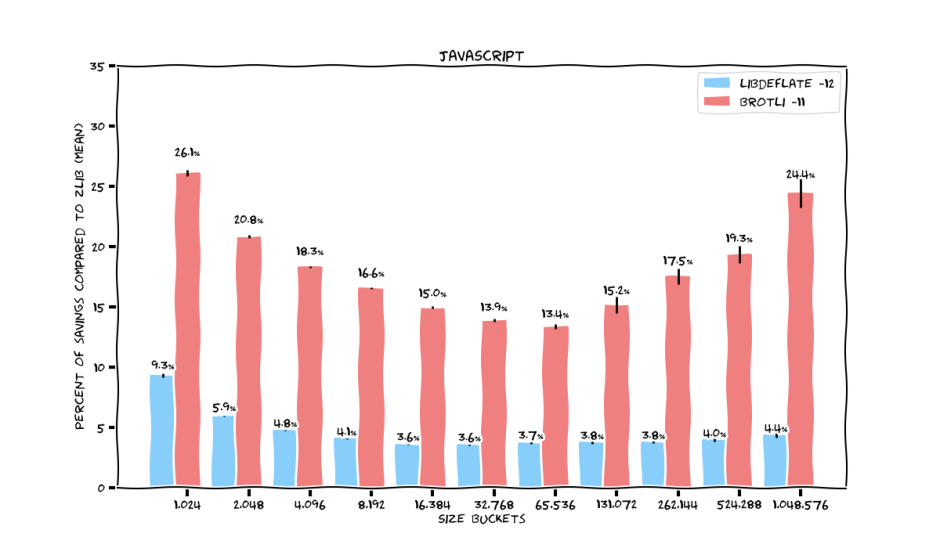
If we now concentrate only on minified JavaScript, which is probably the bulk of any website right now, then Brotli maintains its compression ratios, except for the biggest filesizes. But as you can see from the wide confidence intervals in the box plots, we do not have enough samples there.
Libdeflate drops to a stable ~3% of improvement over zlib.
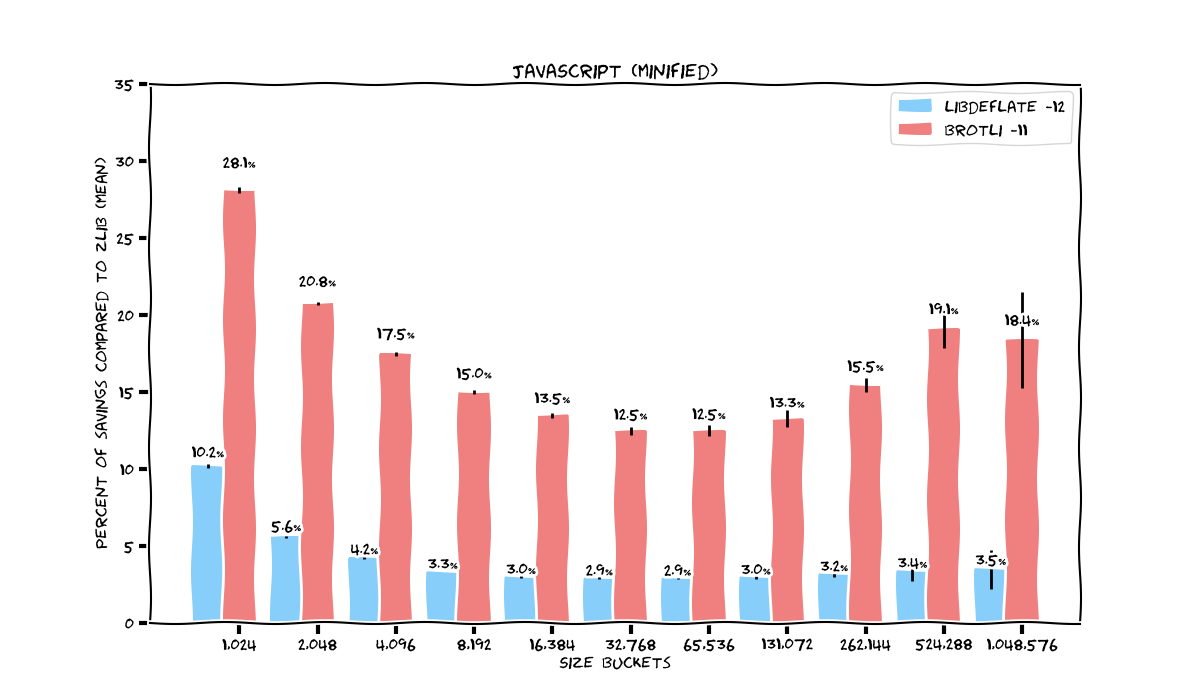
CSS
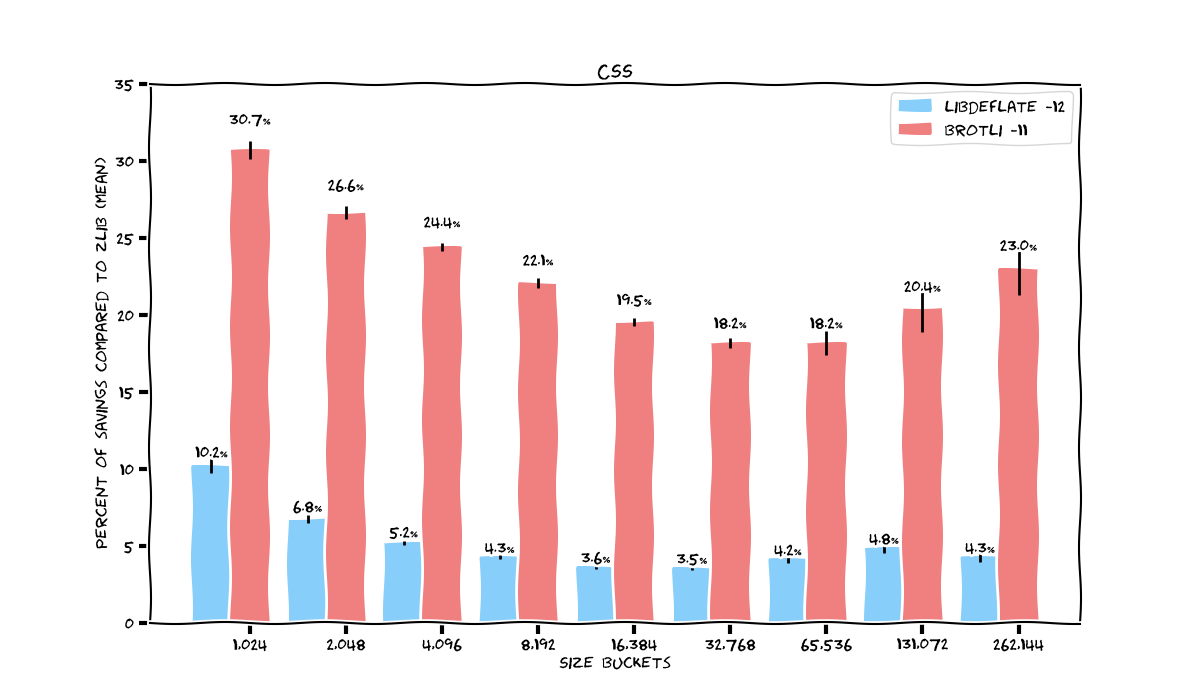
Langpacks
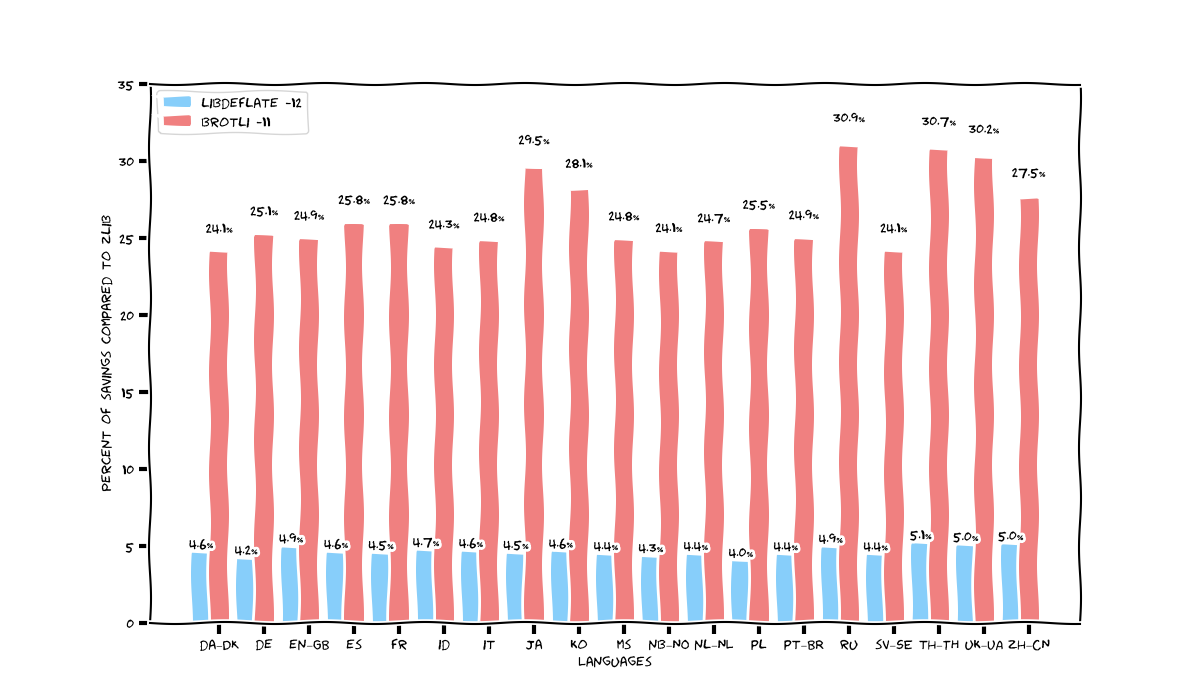
The biggest benefits for Brotli are observed on Cyrillic and Asian languages — upto 31% (most likely due to their larger size, which benefit from Brotli’s larger compression window size). Other languages gets “only” around 25%.
Libdeflate is now closer to 5%.
Negative results
The previous section was actually the second most important part of this post — this section is actually the most important! I’m personally a big fan of sharing negative results, so let me also discuss what we did not get from rolling out Brotli: a major web performance win.
Internally, our main performance metric is Time-To-Interactive (TTI) — i.e., the amount of time it takes before the user can interact with a web page — and we saw only a minor benefit of rolling out Brotli on the 90th-percentile (p90) TTI stats, mainly because:
- Client-side caching works: We store our static files in a content-addressable storage. That, along with proper handling of the
If-None-MatchandIf-Modified-Sinceheaders, causes minimal cache hit disturbances during static deployments. - CDNs are fast: We are currently using Cloudflare as our main CDN. They have over 100 PoPs around the world, which implies that content download is unlikely to be a bottleneck.
- Users of our website are mostly coming from stable internet links: Users coming from mobile ISPs are more likely to use the native Android/iOS apps, which don’t access static assets from a CDN.
- Not all browsers support Brotli: Yeah, Safari, we are talking about you!
- Modern websites are very Javascript-heavy: Sometimes it may take multiple seconds just to parse, compile, execute javascript, and render the webpage. Therefore, the bottleneck is often the CPU, not network bandwidth.
All of this means that you won’t get a 20% TTI win from 20% smaller static files. But that does not mean Brotli was not worth it! Infrequent users of our site, especially those on lossy wireless links or costly mobile data plans will definitely appreciate the improved compression ratios.
On the efficiency side, pre-compression also removed any CPU usage from our web tier serving static content, reducing overall CPU usage by ~15%.
Future work
Compressing dynamic data
The next logical step is to start compressing non-static data with Brotli. This will require a bit more R&D since compression speed now becomes rather crucial. The Squash benchmark can give a ballpark estimation of the compression speed/ratio tradeoff:
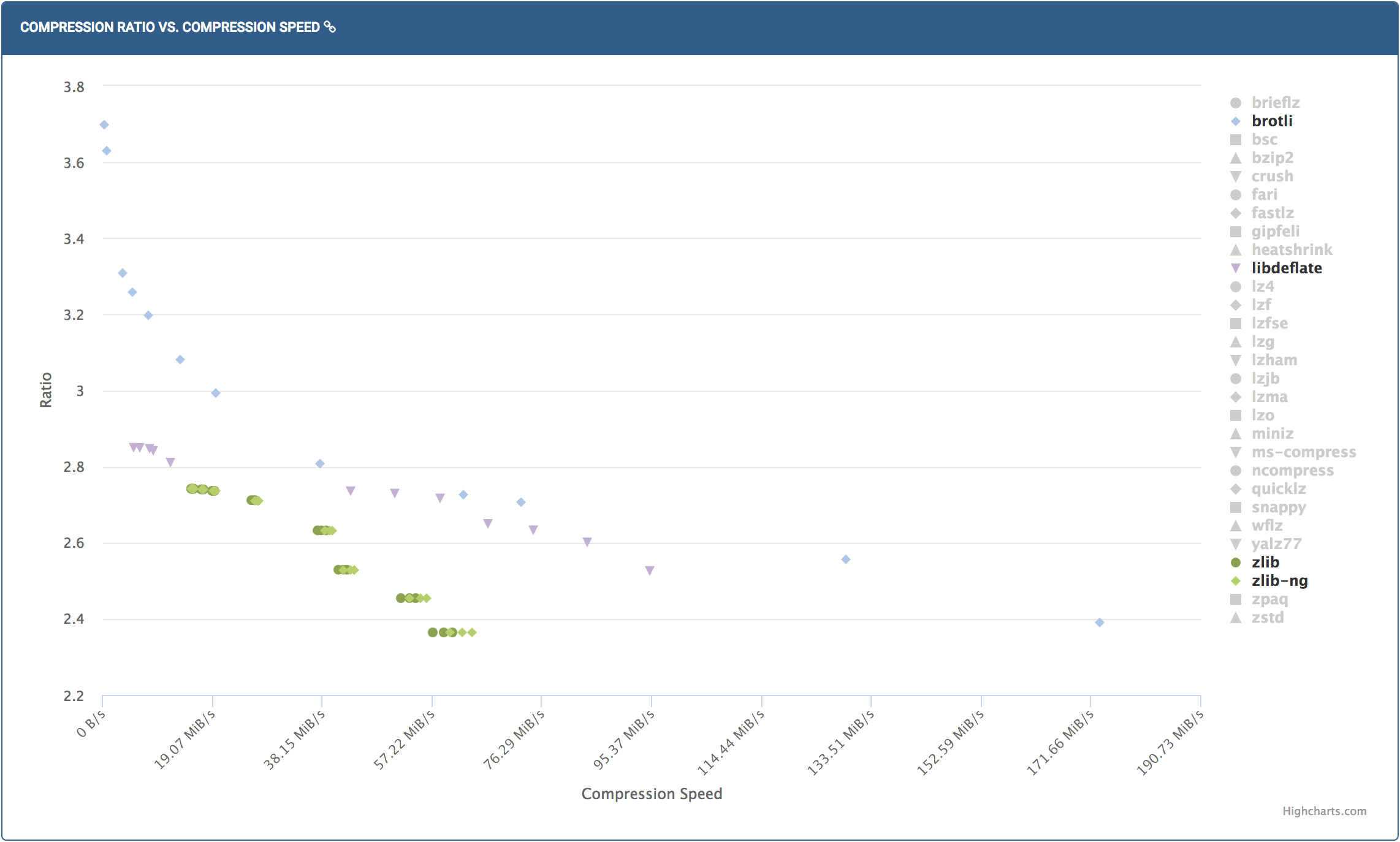
However, it’s actually even more complicated that this chart suggests, since now we need to optimize for (compression_time + transfer_time + decompression_time) while also keeping internal buffering inside our proxy tier at a minimum. An example of bad internal buffering is zlib in the nginx gzip module, where enabling gzip without disabling proxy buffering may lead to excessive buffering. With all of that considered, we will keep a close eye on both Time-To-First-Byte (how fast the client starts to receive data) and Time-To-Last-Byte (how fast the client finishes receiving all data) changes during the Brotli rollout for dynamic content.
It will take us a bit of time to collect enough data to fully explore this, but for now using Brotli with quality set to 5 seems like a good trade-off between compression speed and compression ratio for dynamic data, based on preliminary results.
Image compression data
On average, only 10% of downloaded bytes are attributed to images, but there are outlier pages, such as landing pages which can be 80% images. Brotli won’t help with those, but that doesn’t mean we can’t do other things.
There are many tools that you can plug into your static build pipeline to reduce the size of images. The specific tool to use depends on the image format:
- You can try to optimizing JPEG size (and their Time-To-View) in many different ways:
- Vary quality
- Use different progressive scans
- Switch to a different encoder, e.g. mozjpeg or guetzli
- To get a proper result, all of these require having access to the original non-compressed image, since recompressing JPEGs leads to very poor results.
- On our backend, we are losslessly compressing JPEGs by 22% using Lepton. We also have a prototype of a Javascript Lepton decoder built with Emscripten, but it is not yet fast enough to be used on the web.
- PNG, on the other hand, is a
deflate-based format, so it can be optimized using the samezlibtricks we've discussed earlier. Zopflihas built-in support for losslessly optimizing PNG files via the zopflipng tool (unless you strip metadata chunks from the image).- There are other tools that can do that as well, e.g. advancecomp by Andrea Mazzoleni.
- You can also go with a lossy approach and convert 24bit RBGA images to an 8bit palette, using tools like pngquant.
- Finally, you can also encode images in multiple formats, and if your CDN supports caching based on the
Acceptheader, then you can serve, e.g.,webpimages to browsers that support it.
Currently we use pngquant to optimize our sprite files for our website, which shrinks their size to ~25% of the original size, cutting down each page size by almost 300kB. We can get an additional 5% out of deflate if we run ZopfliPNG/``advpng on top of it.
A final fun fact: because of the rather limited back-reference distance of gzip, grouping visually similar sprites closer together will yield better compression ratios! The same trick can be generally applied to any deflate -compressed data; for example, we sort our langpacks so they compress better.
Conclusion
It took us around 2 weeks to modify our static asset pipeline, add support for serving pre-compressed files to our webservers, and modify CDN cache behavior, test and deploy Brotli to production at Dropbox. This one-time effort enabled us to have 20% smaller static asset footprint from now on for all 500 million of our users!
Appendix: Hacking Brotli
I mentioned that this post wouldn’t go too much into the Brotli internals, but if you want those nitty-gritty details, here are some WebFonts Working Group presentations:
As usual, the most authoritative and full overview is the standard itself: RFC7932 (don’t worry that it is 132 pages long — two thirds of it is just a hex dump of Brotli’s static dictionary).
Speeding up Brotli
Some time ago we’ve blogged about data compression using Brotli on our backend and some modifications we’ve made to it so it can compress quite a bit faster. This ended up as the “q9.5” branch on the Brotli’s official github. However, since this post was about using offline compression for static assets, we are using maximum quality settings here so that we can get the maximum benefits from the compression.
Brotlidump
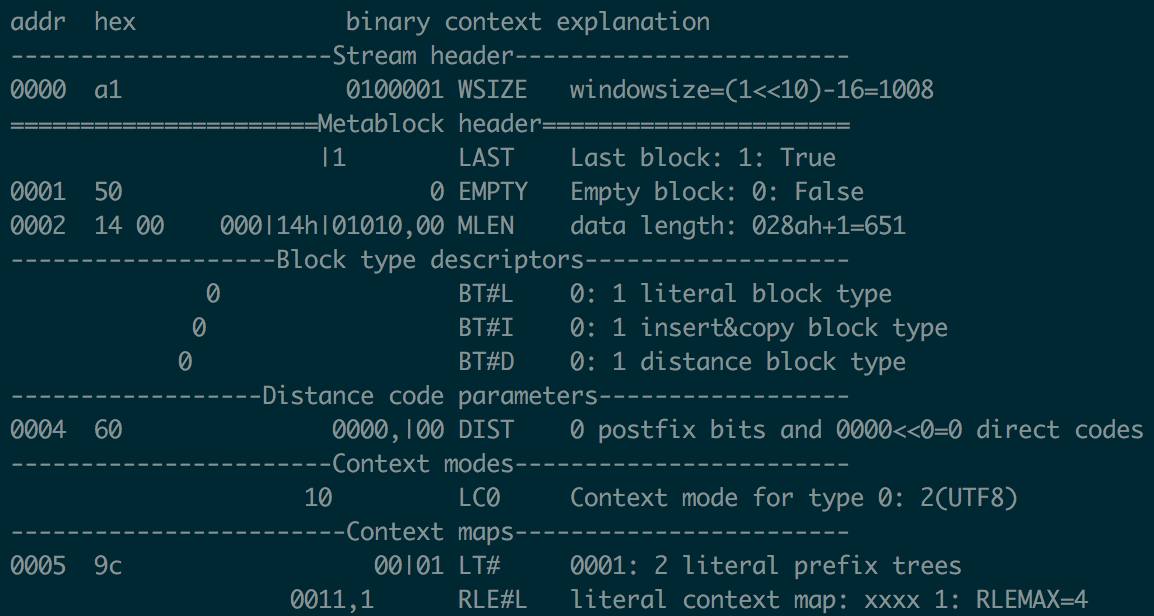
Within the /research directory of the Brotli project there are many interesting tools, mostly aimed at exploring underlying file format and visualizing backreferences.
One notable tool is brotlidump.py — a self-sufficient utility to parse Brotli-compessed files. I’ve used it frequently to look into resulting .br files, e.g. to check window size or inspect context maps.
Custom dictionaries
If you are looking at Brotli for compressing data internally, especially if you have a lot of small and similarly formatted files (e.g. a bunch of JSONs or protobufs from the same API), then you may increase your compression ratio by creating a custom dictionary for your data (the same way SDCH does it). That way you don’t have to rely on Brotli’s built-in static dictionary matching your dataset, and you also won’t have the overhead of constructing almost the same dynamic dictionary for each tiny file.
Support for custom dictionaries exists in Brotli’s Python bindings if you want to play with it. As for constructing dictionaries from a sample of files, I would recommend Vlad Krasnov’s dictator tool.
We're hiring!
Do you like traffic-related stuff? Dropbox has a globally distributed edge network, terabits of traffic, millions of requests per second, and a small team in Mountain View, CA. The Traffic team is hiring both SWEs and SREs to work on TCP/IP packet processors and load balancers, HTTP/2 proxies, and our internal gRPC-based service mesh. Not your thing? We’re also hiring for a wide variety of engineering positions in San Francisco, New York, Seattle, Tel Aviv, and other offices around the world.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}