

In the past few months, we have gradually enabled IPv6 for all user-facing services in Dropbox edge network. We are serving about 15% of daily user requests in IPv6 globally. In this article, we share our experiences and lessons from enabling IPv6 in the edge network. We will cover the IPv6 design in the edge, the changes we made to support IPv6, how IPv6 was tested and rolled out to users, and issues we encountered. Note that this article is not about enabling IPv6 for internal services in our data centers, but rather focuses on making IPv6 available to users.
Why IPv6 in edge network
The Internet Protocol (IP) has been a great success and powers the ever-growing Internet. However, it has long been known that the network address space in Internet Protocol version 4 (IPv4 or v4) would eventually be exhausted. Internet Protocol version 6 (IPv6 or v6) was proposed in the 1990s to address this. Even though the IPv6 transition is inevitable, only recently has IPv6 started to gain a considerable amount of adoption based on measurements from multiple companies and organizations. As announced earlier this year, Dropbox desktop client software already supports working in an IPv6-only environment. Enabling IPv6 for Dropbox services will benefit users who have IPv6 connectivity, prepare us for an IPv6 traffic-heavy network environment in the future, and contribute to the global efforts that promote IPv6 adoption.
The Dropbox edge network consists of multiple Points of Presence (PoPs) distributed globally in order to reduce latency and increase throughput. As of today, the majority of our user traffic (such as web browsing, file uploading & downloading) is served through the edge network. Enabling IPv6 in the edge network will make most of our services operate in a dual-stack environment. We have also added IPv6 support in our data centers (DCs), though it will take more effort to enable IPv6 for all internal services.
IPv6 traffic flow in edge network
Each PoP consists of multiple layer-4 (L4) load balancers and layer-7 (L7) proxies, where our L4 load balancers are built on top of the IPVS kernel module and L7 proxies use the open-source Nginx software. For each service, such as www.dropbox.com, a Virtual IP (VIP) is announced via Border Gateway Protocol (BGP), and this VIP is also advertised in DNS. User traffic sent to this VIP is distributed to IPVS based on equal-cost multi-path routing by routers in the PoP. IPVS then forwards traffic to Nginx, which performs early TLS termination and proxies user traffic via secured HTTPs connections to DCs. We leverage Direct Server Reply (DSR) for the HTTPs responses (i.e., egress traffic) so that IPVS only needs to process ingress traffic.
Why IPv6 in edge network
The Internet Protocol (IP) has been a great success and powers the ever-growing Internet. However, it has long been known that the network address space in Internet Protocol version 4 (IPv4 or v4) would eventually be exhausted. Internet Protocol version 6 (IPv6 or v6) was proposed in the 1990s to address this. Even though the IPv6 transition is inevitable, only recently has IPv6 started to gain a considerable amount of adoption based on measurements from multiple companies and organizations. As announced earlier this year, Dropbox desktop client software already supports working in an IPv6-only environment. Enabling IPv6 for Dropbox services will benefit users who have IPv6 connectivity, prepare us for an IPv6 traffic-heavy network environment in the future, and contribute to the global efforts that promote IPv6 adoption.
The Dropbox edge network consists of multiple Points of Presence (PoPs) distributed globally in order to reduce latency and increase throughput. As of today, the majority of our user traffic (such as web browsing, file uploading & downloading) is served through the edge network. Enabling IPv6 in the edge network will make most of our services operate in a dual-stack environment. We have also added IPv6 support in our data centers (DCs), though it will take more effort to enable IPv6 for all internal services.
IPv6 traffic flow in edge network
Each PoP consists of multiple layer-4 (L4) load balancers and layer-7 (L7) proxies, where our L4 load balancers are built on top of the IPVS kernel module and L7 proxies use the open-source Nginx software. For each service, such as www.dropbox.com, a Virtual IP (VIP) is announced via Border Gateway Protocol (BGP), and this VIP is also advertised in DNS. User traffic sent to this VIP is distributed to IPVS based on equal-cost multi-path routing by routers in the PoP. IPVS then forwards traffic to Nginx, which performs early TLS termination and proxies user traffic via secured HTTPs connections to DCs. We leverage Direct Server Reply (DSR) for the HTTPs responses (i.e., egress traffic) so that IPVS only needs to process ingress traffic.
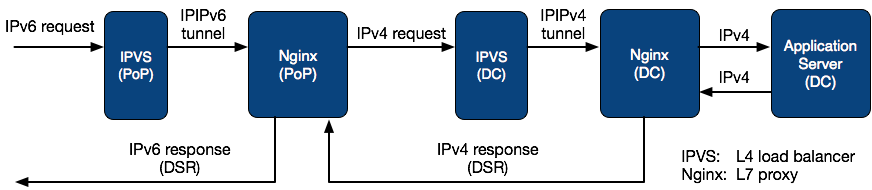
The figure above shows the IPv6 traffic flow in our edge network. IPv6 requests are forwarded by IPVS to Nginx via IPv6 in IPv6 (IPIPv6) tunnels. Nginx then proxies these requests to DCs in IPv4. Similar load balancing schemes apply when IPv4 requests reach DCs and then get delivered to application servers, though everything happens in IPv4. Essentially, IPv6 requests are terminated at PoPs.
IPv6 network design
In Q4 2016 we started rolling out IPv6 across our entire network. We started first with dual-stacking all our links followed by making necessary changes to our routing protocols to support v6. Intermediate System to Intermediate System (IS-IS) which is a protocol-agnostic architecture and can easily support all address types including v4 and v6. This was our Interior Gateway Protocol (IGP) in the backbone, so there was no significant changes we had to make to support v6 for IS-IS. To have consistent routing for both v4 and v6, we chose IS-IS single-topology over multi-topology.
After IS-IS, we had to make changes to BGP. We deployed separate BGP sessions for v4 and v6 but maintained the same routing policies across both of them to ensure routing symmetry. The third piece was Multi-Protocol Label Switch (MPLS-TE) that was deployed across our backbone to forward v4 traffic. We intended to use the same set of Label Switch Paths (LSPs) to forward v6 traffic. We could achieve that by using IGP short-cuts as defined in RFC3906. With the implementation of IGP-shortcuts, both v6 and v4 traffic were using the same set of MPLS-LSPs across the backbone. By the end of Q1 2017 we completed v6 roll-out across our data centers, backbone, and edge.
As for public IPv6 address allocation, each PoP has a unique /48 address space which is advertised to external peers by the edge router in that PoP. Announcing the /48 v6 prefix to the external world only from that PoP guarantees that all user requests to an IPv6 VIP which belongs to this /48 address space enter Dropbox network via that PoP and terminate locally on the Ngnix machines in that PoP. Each /128 IPv6 VIP has a unique /64 prefix, and we announce this /64 prefix instead of the full /128 address from IPVS to routers in the PoP to be more memory-efficient (though only traffic sent to the /128 VIPs will be accepted in the PoPs). The IPv4 VIP is embedded as the last 32 bits of the IPv6 VIP to make it more operational friendly.
Software stack updates
The software stack in PoPs needed to be fully IPv6 compatible to handle IPv6 traffic. The applications running in our data centers also needed to be updated to properly work with client-side IPv6 addresses passed along in the X-Forwarded-For headers by Nginx.
In our PoPs, both the IPVS kernel module and Nginx software support IPv6 natively, though we needed to update the in-house configuration management tools for them to work with IPv6. We use IPv6 in IPv6 tunneling between IPVS and Nginx so that the tunneled IPv6 user traffic can be correctly decapsulated on the Nginx side. Because IPv6 packet headers are longer than the ones in IPv4, the advertised TCP Maximum Segment Size (MSS) was reduced to 1400 bytes to work with tunneling.
On the data center side, we updated our application servers to properly handle client-side IPv6 addresses embedded in the X-Forwarded-For header. The following lists some common IPv6 compatibility issues we saw when updating our code base:
- IPv6 address format: IPv6 addresses have a different format from IPv4 addresses, so code written with the assumption of IPv4 format would break, such as splitting the IP address by dot. Additionally, IPv6 addresses have multiple representation formats, so it’s always a good idea to unify the IPv6 address format before performing operations.
- Regular expressions: Regular expressions used for detecting IP addresses might only handle IPv4. These regular expressions need to be updated to work with IPv6. And again, keep in mind that there could be multiple ways to represent an IPv6 address.
- GeoIP library: The GeoIP library and databases may need to be updated to support looking up IPv6 addresses. The C extension could be helpful for optimizing performance.
- Access control: Last but not least, access control software and rulesets need to be updated to be IPv6 compatible.
Roullout
We first deployed IPv6 support in our infrastructure so that we could test without affecting production traffic. After that, we gradually enabled IPv6 for users, service by service. In this section, we present the rollout process in detail and the issues we encountered.
Deploy IPv6 support in our infrastructure
IPv6 was first deployed to our network infrastructure so that we had IPv6 working at PoPs. After that, we deployed the updated IPVS and Nginx software, at which point we started to announce IPv6 VIPs via BGP. The deployment was done PoP by PoP to minimize risks. The IPv6 VIPs were not added to DNS, so they were not visible to users. In this step, we tested IPv6 reachability and performance. In the meantime, internal teams could leverage these VIPs to perform end-to-end IPv6 testing for their codes in the application servers.
Enable IPv6 for user-facing services
To enable IPv6 for a service, we need to add an AAAA record for the related domain(s), and users will receive the IPv6 VIP when performing AAAA DNS queries. To support a smooth transition from IPv4-only to dual-stack network environments, efforts such as Happy Eyeball have been proposed and implemented in many client-side software (such as browsers and the Dropbox desktop client). In these software, clients prefer IPv6 connections but are still able to fall back to IPv4 if the IPv6 connection is broken or not performing well. As for DNS, either parallel DNS queries will be made, or AAAA DNS queries will be sent ahead of A queries.
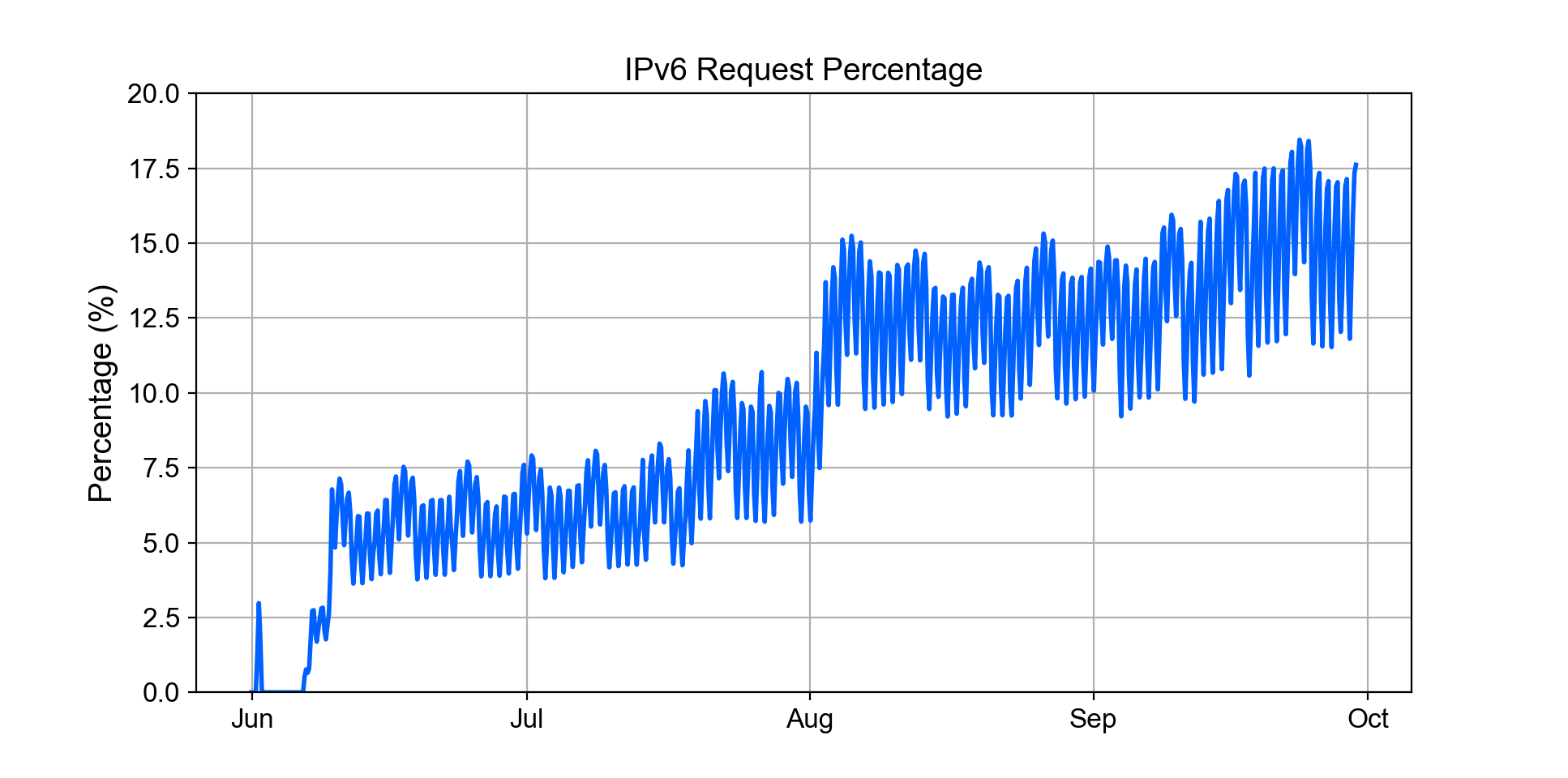
In the rollout process, IPv6 was enabled service by service, so that we could monitor the status and performance, as well as isolate the impact if something went wrong. To enable a new service, we typically performed an office test, a user traffic test, and then rolled out to production. The figure above shows the increased IPv6 request percentage (each data point represents the average during a 4-hour time window) as we gradually enabled IPv6 for more services in the edge network. Note that the spike at the beginning of June is from a user traffic test.
Issues during deployment
We ran into some initial hiccups during IPv6 deployment.
One of them was whitelisting v6 /48 address from each PoP with our external peers. We learned that registering our v6 address space with RADb was not sufficient. We had to reach out to some of our providers to update their Access Control Lists (ACLs) to accept v6 routes. Unfortunately this occurrence seemed to be a lot more common than we anticipated which resulted in sub-optimal routing issues during our initial deployment. Luckily we could catch most of the anomalies during our internal testing before rolling it out to external users.
We had to update our ACLs to accommodate for new functionality and roles that ICMPv6 has in the overall operation of IPv6, most common of which was Neighbor Discovery (ND). We had to reshuffle some of our ACL terms in accordance to RFC6192 to permit ICMPv6 above all other terms. Before doing that, we were very frequently running into issues while bringing up v6 eBGP peers as ND packets were getting blocked by our ACLs.
DNS NXDOMAIN responses for AAAA queries are dangerous. Most dual-stack software will ensure a broken IPv6 connection has the opportunity to fall back to IPv4 to support a smooth transition from IPv4-only to dual-stack networks. However, DNS still represents a place where an IPv6-specific issue cannot easily fall back to IPv4 and may affect IPv4 as well. An NXDOMAIN response for AAAA queries essentially means there are not any records (neither A nor AAAA) exist. In this case, client software may not retry IPv4. Additionally, A queries could also be affected and receive NXDOMAIN if DNS resolvers cache the AAAA NXDOMAIN response. On a related note, Cloudflare has proposed an alternative DNS record type TYPE65536 that contains both A and AAAA answers, but for the purpose of reducing the overhead of additional DNS queries.
IPv6 statistics and performance
After IPv6 is enabled for all services in the edge network, we see about 15% of daily user requests reach us in IPv6 globally. PoPs in the US receive the highest IPv6 request percentages, followed by PoPs in Europe and APAC regions.
IPv6 statistics
To understand the IPv6 deployment status, we have measured the percentage of IPv6 requests across all Dropbox services with sampled traffic (last 15 minutes of each hour) on September 20th, 2017 (Wednesday). We present the IPv6 statistics for different countries/regions and ISPs.
Countries/Regions. The heat map below shows the average IPv6 traffic percentage for each country. In this map, a darker blue color means higher percentage of IPv6 requests.
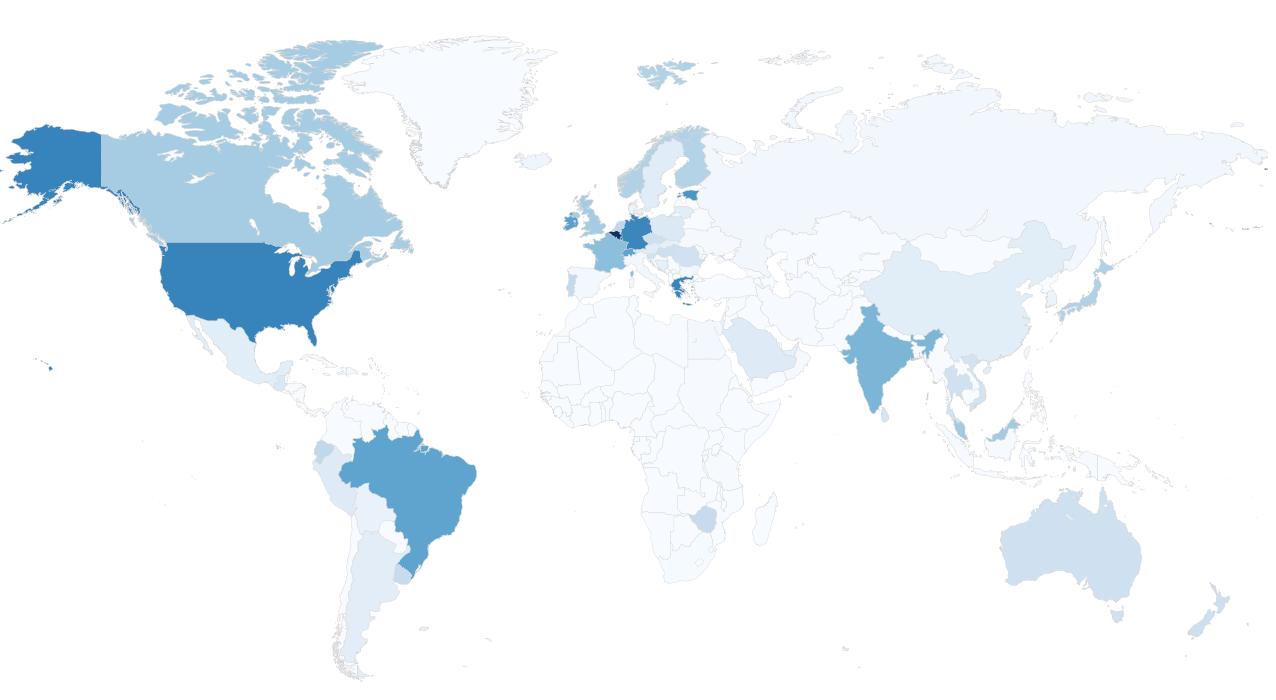
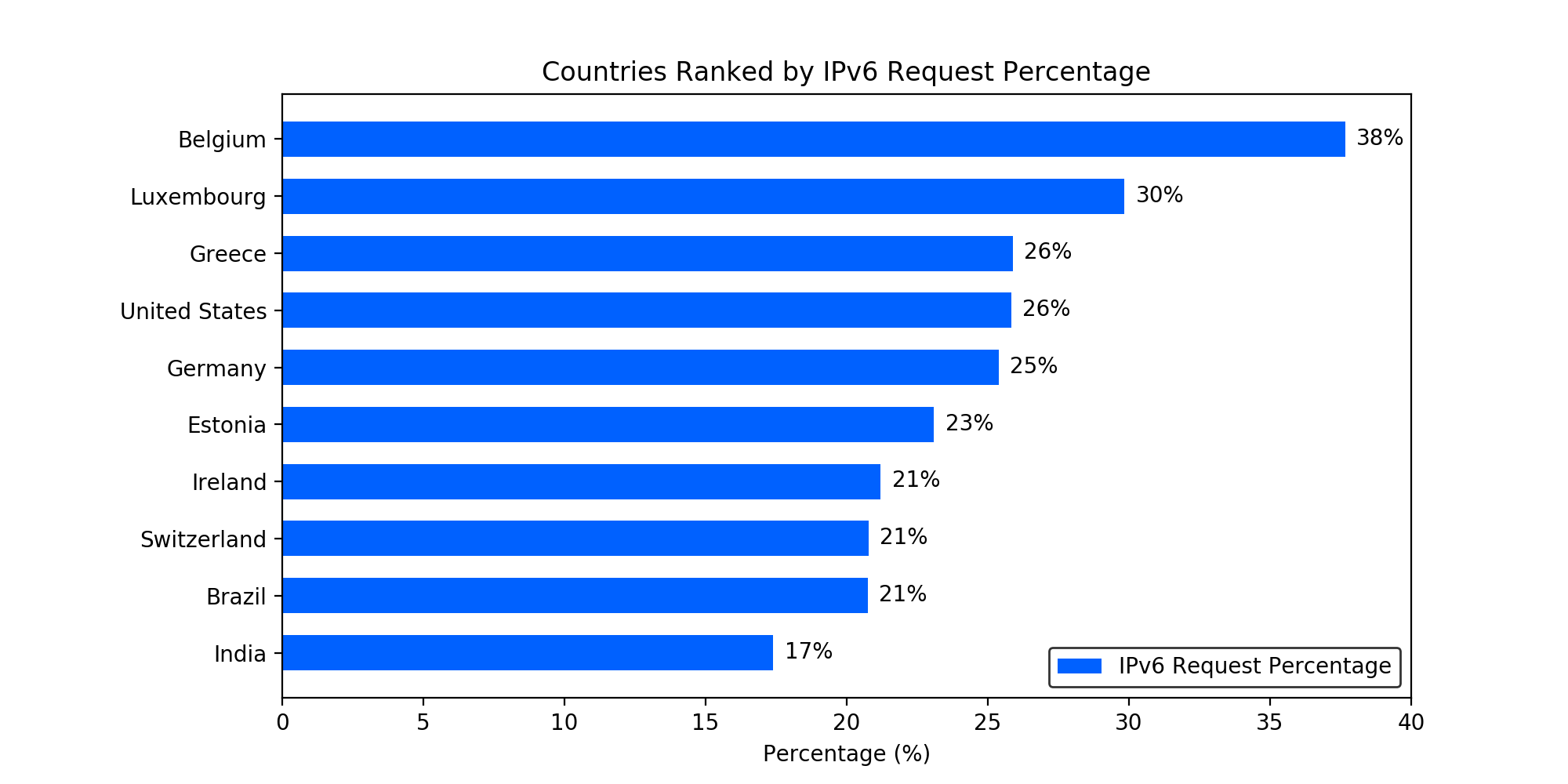
Similar as reported from others, we see higher IPv6 request rates in some European countries and the US. We also observe considerable IPv6 deployments in South America and the APAC region. The following figure lists the top 10 countries ranked by the IPv6 request percentage.
ISPs. We have also looked into IPv6 statistics among ISPs. We selected the top 10 ISPs in terms of total number of IPv6 requests sent to our edge network during the measurement, and the following figure lists these ISPs ranked by IPv6 request percentage. We label each ISP with the continent code (i.e.., EU for Europe, SA for South America, and NA for North America) and a unique index within that continent. As can be seen, the top two ISPs (both are US mobile carriers) are getting close to 100% IPv6.
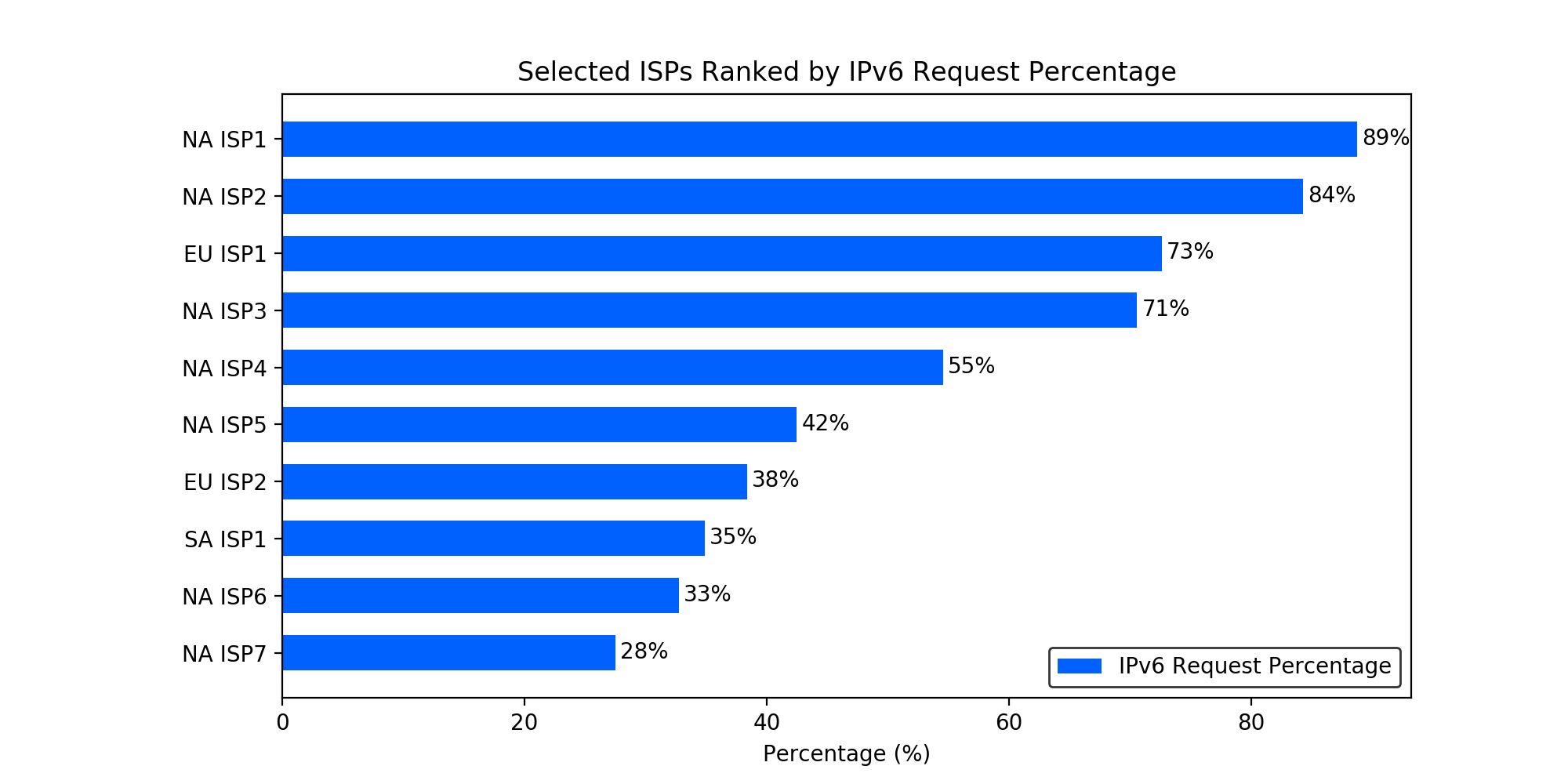
The following is a list of IPv6 statistics reported from other organizations:
Performance
It has been reported that IPv6 has better network performance compared to IPv4, especially in mobile networks. To understand IPv6 performance, we have measured the TCP Round Trip Time (RTT) on our API endpoint ( api.dropbox.com), which is used mostly by our mobile clients. We have also looked into desktop client file download performance.
TCP Round Trip Time. Many factors could contribute to the performance differences of IPv4 and IPv6, such as the additional delays introduced by NAT64/DNS64, performance advantages of newer hardware, client device performance, etc. Providing a fair IPv4 and IPv6 comparison is challenging. Ideally, the performance measurement should take place on the same client at the same time to minimize the impact of other factors. As we don’t have that capability from the server side, during our initial IPv6 deployment for the api endpoint ( api.dropbox.com), we enabled IPv6 for only 50% of users via DNS for a few hours. This way, for an IPv6-heavy network (such as two of the US major mobile carriers), approximately 50% of users would connect to us via IPv6 while the other half via IPv4. We chose the api endpoint for this measurement because our mobile apps talk to this endpoint and thus most traffic will be from cellular networks.
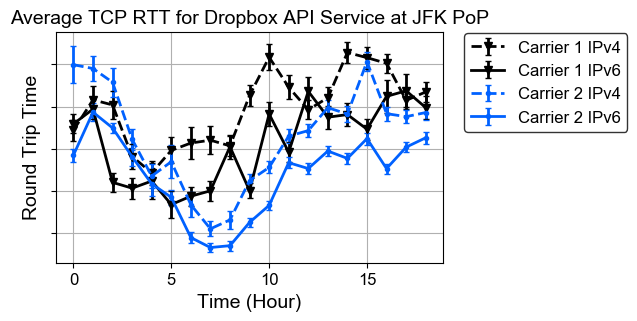
We compared the TCP RTT performance for IPv4 and IPv6 connections. The TCP round trip time was measured using the TCP_INFO socket option, and the results were reported via the tcpinfo_rtt variable provided by Nginx. We could also look into TCP retransmission stats using tcpi_total_retrans, but because we have enabled BBR in our edge network, packet losses would not affect the throughput as significantly as when other congestion algorithms, such as cubic, were used. The above graph shows the average RTT values (with 95% confidence intervals) reported for clients from two US cellular networks that we knew were close to 100% IPv6. As can be seen from the figure, IPv6 does show slightly better performance over IPv4. However, without detailed client-side and network information, it is hard to say definitely where the IPv6 performance gain is from. Additionally, the actual time needed for each request also depends on the performance of application servers.
File download speeds. File syncing is one of the most important functions people use Dropbox for, thus we looked into desktop client file download speeds after IPv6 was enabled. We calculated the download speeds based on HTTP response body lengths and request time collected on Nginx proxies in our JFK PoP. Only files that were larger than 100KB were included in the study to exclude the potential variance introduced by small files. Since file download performance could differ based on user’s ISP networks, we focused on file download speeds for users from the ISP that sent the largest number of IPv6 requests to us. Because this ISP was not yet close to 100% IPv6 based on our stats, we compared week-over-week (Mondays) file download speeds after IPv6 was enabled.
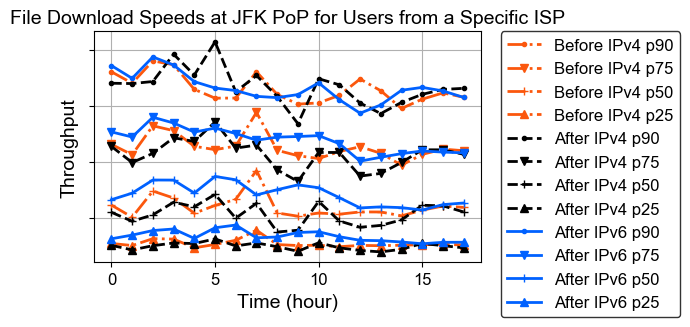
The figure above shows the file download speeds with different percentiles (pXX) for IPv4 and IPv6 after IPv6 was enabled, as well as the performance for IPv4 one week earlier (both were Mondays). From the figure, IPv6 file download speeds are faster than IPv4 after we enabled IPv6 at most percentiles, and the P90 performance (fastest download speeds) is comparable to IPv4. However, it is worth noting that this is not a strictly fair comparison because other factors could have contributed to the IPv6 performance gain. Comparing IPv6 performance with the IPv4 performance one week earlier, we could say that IPv6 performance is comparable to IPv4, and for lower percentiles, i.e., slower file download speeds, IPv6 also shows slightly better performance. Again, this is not a perfect comparison for IPv4 and IPv6, but we hope this provides some additional information for people who are interested in IPv6 performance.
Conclusion
In this article, we’ve shared our experiences of enabling IPv6 in our network. The challenges of the overall process have been greatly reduced as hardware and protocol support for IPv6 become more mature. The majority of our efforts were on deploying IPv6 in our infrastructure, updating our software stack to be IPv6 compatible, testing, and gradually rolling out to users. We hope this article is helpful for those who are looking into enabling IPv6 for their front-end services and also those who are interested in IPv6 in general, and we look forward to hearing your feedback.
Contributors to this article: Alexey Ivanov, Dzmitry Markovich, Haowei Yuan, Naveen Oblumpally, and Ross Delinger
We're hiring!
Do you like traffic-related stuff? Dropbox has a globally distributed edge network, terabits of traffic, millions of requests per second, and a small team in Mountain View, CA. The Traffic team is hiring both SWEs and SREs to work on TCP/IP packet processors and load balancers, HTTP/2 proxies, and our internal gRPC-based service mesh. Not your thing? We’re also hiring for a wide variety of engineering positions in San Francisco, New York, Seattle, Tel Aviv, and other offices around the world.


