


Over the last few months, the Search Infrastructure engineering team at Dropbox has been busy releasing a new full-text search engine called Nautilus, as a replacement for our previous search engine.
Search presents a unique challenge when it comes to Dropbox due to our massive scale—with hundreds of billions of pieces of content—and also due to the need for providing a personalized search experience to each of our 500M+ registered users. It’s personalized in multiple ways: not only does each user have access to a different set of documents, but users also have different preferences and behaviors in how they search. This is in contrast to web search engines, where the focus on personalization is almost entirely on the latter aspect, but over a corpus of documents that are largely the same for each user (localities aside).
In addition, some of the content that we’re indexing for search changes quite often. For example, think about a user (or several users) working on a report or a presentation. They will save multiple versions over time, each of which might change the search terms that the document should be retrievable by.
More generally, we want to help users find the most relevant documents for a given query—at this particular moment in time—in the most efficient way possible. This requires being able to leverage machine intelligence at several stages in the search pipeline, from content-specific machine learning (such as image understanding systems) to learning systems that can better rank search results to suit each user’s preferences.
The Nautilus team worked with our machine intelligence platform to scale our search ranking and content understanding models. These kind of systems require a lot of iteration to get right, and so it is crucial to be able to experiment with different algorithms and subsystems, and gradually improve the system over time, piece-by-piece. Thus, the primary objectives we set for ourselves when starting the Nautilus project were to:
- Deliver best-in-class performance, scalability, and reliability to deal with the scale of our data
- Provide a foundation for implementing intelligent document ranking and retrieval features
- Build a flexible system that would allow our engineers to easily customize the document-indexing and query-processing pipelines for running experiments
- And, as with any system that manages our users’ content, our search system needed to deliver on these objectives quickly, reliably, and with strong safeguards to preserve the privacy of our users’ data
In this blog post we describe the architecture of the Nautilus system and its key characteristics, provide details about the choices we made in terms of technologies and approaches we chose for the design, and explain how we make use of machine learning (ML) at various stages of the system.
High level architecture
Nautilus consists of two mostly-independent sub-systems: indexing and serving.
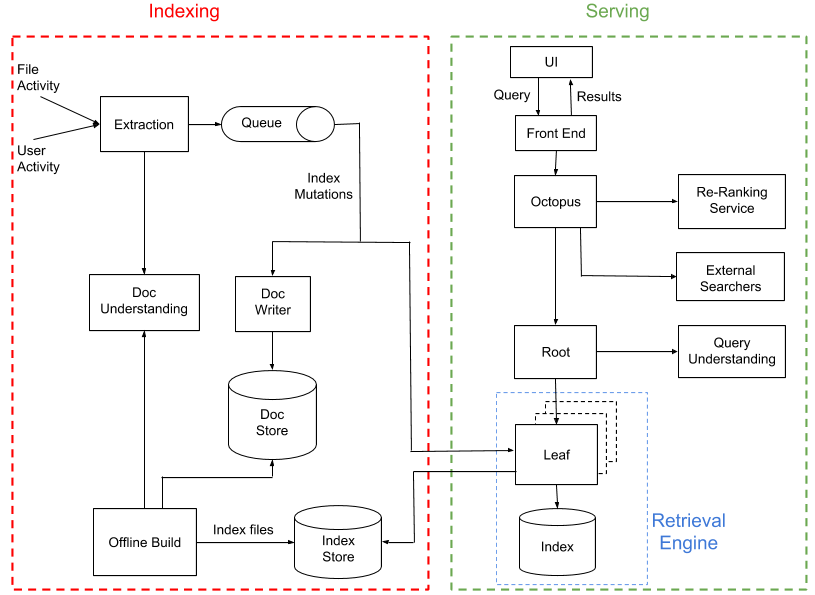
The role of the indexing pipeline is to process file and user activity, extract content and metadata out of it, and create a search index. The serving system then uses this search index to return a set of results in response to user queries. Together, these systems span several geographically-distributed Dropbox data centers, running tens of thousands of processes on more than a thousand physical hosts.
The simplest way to build an index would be to periodically iterate through all files in Dropbox, add them to the index, and then allow the serving system to answer requests. However, such a system wouldn’t be able to keep up with changes to documents in anything close to real-time, as we need to be able to do. So we follow a hybrid approach which is fairly common for search systems at large scale:
- We generate “offline” builds of the search index on a regular basis (every 3 days, on average)
- As users interact with files and each other, such as editing files or sharing them with other users, we generate “index mutations” that are then applied to both the live index and to a persistent document store, in near real-time (on the order of a few seconds).
Some other key pieces of the system that we’ll talk about are how to index different kinds of content, including using ML for document understanding and how to rank retrieved search results (including from other search indexes) using an ML-based ranking service.
Data sharding
Before we talk about specific subsystems in Nautilus, let’s briefly discuss how we can achieve the level of scale we need. With hundreds of billions of pieces of content, we have an enormous amount of data that we need to index. We split, or “shard,” this data across multiple machines. To do this, we need to decide how to shard files such that search requests for each user complete quickly, while also balancing load relatively evenly across our machines.
At Dropbox, we already have such a schema for grouping files, called a “namespace,” which can be thought of as a folder that one or more users have access to. One of the benefits of this approach is it allows us to only see search results from files that they have access to, and it is how we allow for shared folders. For example: the folder becomes a new namespace that both sharer and share recipient have access to. The set of files a Dropbox user can access is fully defined by the set of underlying namespaces she was granted access to. Given the above properties of namespaces, when a user searches for a term, we need to search all of the namespaces that they have access to and combine the results from all matches. This also means that by passing the namespaces to the search system we only search content that the querying user can access at the time the search is executed.
We group a number of namespaces into a “partition,” which is the logical unit over which we store, index, and serve the data. We use a partitioning scheme that allows us to easily repartition namespaces in the future, as our needs change.
Indexing
Document extraction and understanding
What are the kinds of things users would like to search by? Of course there is the content of each document, i.e., the text in the file. But there are also numerous other types of data and metadata that are relevant.
We designed Nautilus to flexibly handle all of these and more, through the ability to define a set of “extractors” each of which extracts some sort of output from the input file and writes to a column in our “document store.” The underlying technology has extra custom built layers that provide access control and data encryption. It contains one row per file, with each column containing the output from a particular extractor. One significant advantage of this schema is that we can easily update multiple columns on a row in parallel without worrying about changes from one extractor interfering with those from others.
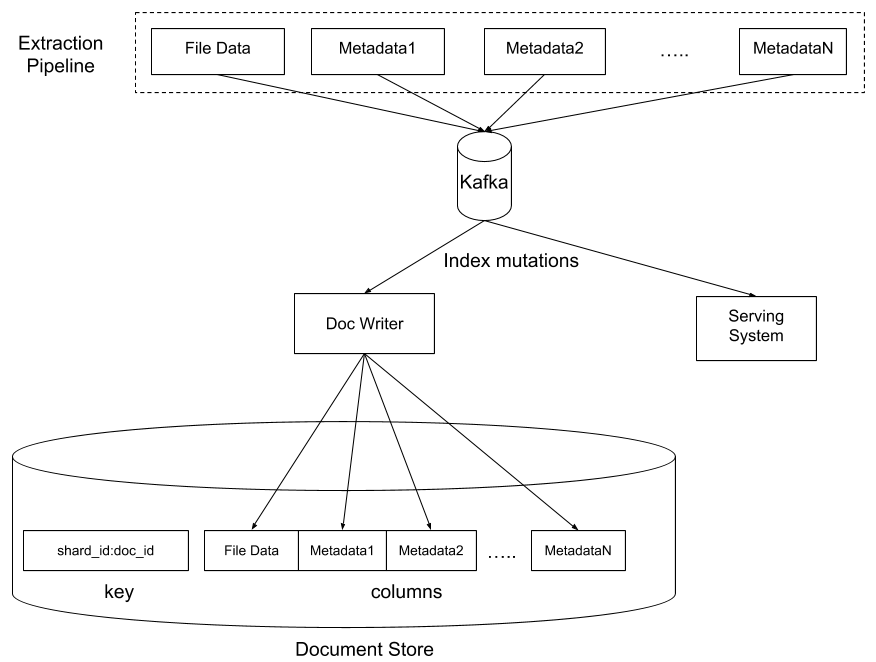
For most documents, we rely on Apache Tika to transform the original document into a canonical HTML representation, which then gets parsed in order to extract a list of “tokens” (i.e. words) and their “attributes” (i.e. formatting, position, etc…).
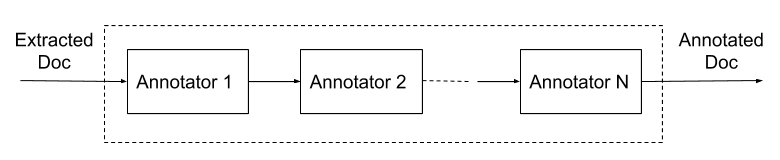
After we extract the tokens, we can augment the data in various ways using a “Doc Understanding” pipeline, which is well suited for experimenting with extraction of optional metadata and signals. As input it takes the data extracted from the document itself and outputs a set of additional data which we call “annotations.” Pluggable modules called “annotators” are in charge of generating the annotations. An example of a simple annotator is the stemming module which generates stemmed tokens based on raw tokens. Another example is converting tokens to embeddings for more flexible search.
Offline build
The document store contains the entire search corpus, but it is not well-suited for running searches. This is because it stores extracted content mapped by document id. For search, we need an inverted i ndex: a mapping from search term to list of documents. The offline build system is in charge of periodically re-building this search index from the document store. It runs the equivalent of a MapReduce job on our document store in order to build up a search index that can be queried extremely fast. Each partition ends up with a set of index files that are stored in an “index store.”
By separating the document extraction process from the indexing process, we gain a lot of flexibility for experiments:
- Modification of the internal format of the index itself, including the ability to experiment on a new index format that improves retrieval performance or reduces storage costs.
- Applying a new document annotator to the entire corpus. Once an annotator has demonstrated benefits when applied to the stream of fresh documents flowing in the instant indexing pipeline, it can be applied to the entire corpus of documents within a couple days by simply adding it to the offline build pipeline. This increases experimentation velocity compared to having to run large backfill scripts for updating the data corpus in the document store.
- Improving the heuristics used for filtering the data that gets indexed. Not surprisingly, when dealing with hundreds of billions of pieces of content, we have to protect the system from edge cases that could cause accuracy or performance degradations, e.g., some extremely large documents or documents that were incorrectly parsed and generate garbled tokens. We have several heuristics for filtering out such documents from the index, and we can easily update these heuristics over time, without having to reprocess the source documents every time.
- Ability to mitigate an unforeseen issue caused by a new experiment. If there is some error in the indexing process, we can simply rollback to a previous version of the index. This safeguard translates to a higher tolerance for risk and speed of iteration when experimenting.
Serving
The serving system is comprised of a front-end, which accepts and forwards user search queries; a retrieval engine which retrieves a large list of matching documents for each query; and a ranking system named Octopus that ranks results from multiple back-ends using machine learning. We’ll focus here on the latter two, as the front-end is a fairly straightforward set of APIs that all our clients use (web, desktop, and mobile).
Retrieval engine
The retrieval engine is a distributed system which fetches documents that match a search query. The engine is optimized for performance and high recall—it aims to return the largest set of candidates possible in the given allocated time budget. These results will then be ranked by Octopus, our search orchestration layer, to achieve high precision, i.e., ensure that the most relevant results are highest in the list. The retrieval engine is divided into a set of “leaves” and a “root”:
- The root is primarily in charge of fanning out incoming queries to the set of leaves holding the data, and then receiving and merging results from the leaves, before returning them to Octopus.
- The root also includes a “query understanding” pipeline which is very similar to the doc understanding pipeline we discussed above. The purpose of this is to transform or annotate a query to improve retrieval results.
- Each leaf handles the actual document lookup for a group of namespaces. It manages the inverted and forward document index. The index is periodically seeded by downloading a build from the offline build process, and is then continuously updated by applying mutations consumed from Kafka queues.
Search Orchestrator
Our Search Orchestration layer is called Octopus. Upon receiving a query from a user, the first task performed by Octopus is to call Dropbox’s access-control service to determine the exact set of namespaces the user has read access to. This set defines the “scope” of the query that will be performed by the downstream retrieval engine, ensuring that only content accessible to the user will be searched.
Besides fetching results from the Nautilus retrieval engine, we have to do a couple things before we can return a final set of results to the user:
- Federation: In addition to our primary document store and retrieval engine (described above), we also have a few separate auxiliary backends that need to be queried for specific types of content. One example of this is Dropbox Paper documents, which currently run on a separate stack. Octopus provides the flexibility to send search queries to and merge results from multiple backend search engines.
- Shadow engines: The ability to serve results from multiple backends is also extremely useful for testing updates to our primary retrieval engine backend. During the validation phase, we can send search queries to both the production system and the new system being tested. This is often referred to as “shadow” traffic. Only results from the production system are returned to the user, but data from both systems is logged for further analysis, such as comparing search results or measuring performance differences.
- Ranking: After collecting the list of candidate documents from the search backends, Octopus fetches additional signals and metadata as needed, before sending that information to a separate ranking service, which in turn computes the scores to select the final list of results returned to the user.
- Access Control (ACL) checks: In addition to the retrieval engine restricting the search to the set of namespaces defined in the query scope, an additional layer of protection is added at the Octopus layer by double checking that each result returned by the retrieval engine can be accessed by the querying user before returning them.
Note that all of these steps have to happen very fast—we target a budget of 500ms for the 95th percentile search (i.e., only 5% of searches should ever take longer than 500ms). In a future blog post, we will describe how we make that happen.
Machine learning powered ranking
As mentioned earlier, we tune our retrieval engine to return a large set of matching documents, without worrying too much about how relevant each document is to the user. The ranking step is where we focus on the opposite end of the spectrum: picking the documents that the user is most likely to want right now. (In technical terms, the retrieval engine is tuned for recall, while the ranker is tuned for precision.)
The ranking engine is powered by a ML model that outputs a score for each document based on a variety of signals. Some signals measure the relevance of the document to the query (e.g., BM25), while others measure the relevance of the document to the user at the current moment in time (e.g., who the user has been interacting with, or what types of files the user has been working on).
The model is trained using anonymized “click” data from our front-end, which excludes any personally identifiable data. Given searches in the past and which results were clicked on, we can learn general patterns of relevance. In addition, the model is retrained or updated frequently, adapting and learning from general users’ behaviors over time.
The main advantage of using an ML-based solution for ranking is that we can use a large number of signals, as well as deal with new signals automatically. For example, you could imagine manually defining an “importance” for each type of signal we have available to us, such as which documents the user interacted with recently, or how many times the document contains the search terms. This might be doable if you only have a handful of signals, but as you add tens or hundreds or even thousands of signals, this becomes impossible to do in an optimal way. This is exactly where ML shines: it can automatically learn the right set of “importance weights” to use for ranking documents, such that the most relevant ones are shown to the user. For example, by experimentation, we determined that freshness-related signals contribute significantly to more relevant results.
Conclusion
After a period of qualification where Nautilus was running in shadow mode, it is currently the primary search engine at Dropbox. We’ve already seen significant improvements to the time-to-index new and updated content, and there’s much more to come.
Now that we have solid foundations in place, our team is busy building on top of the Nautilus platform to add new features and improve search quality. We’re exploring new capabilities, such as augmenting the existing posting-list-retrieval-algorithm with distance-based retrieval in an embedding space; unlocking search for image, video, and audio files; improving personalization using additional user activity signals; and much more. Find out about how we validated the performance and reliability of Nautilus in the second part of this post.
Nautilus is a prime example of the type of large scale projects involving data retrieval and machine learning that engineers at Dropbox tackle. If you are interested in these kinds of problems, we would love to have you on our team.
Thanks to: Adam Faulkner, Adhiraj Somani, Alan Shieh, Annie Zhou, Braeden Kepner, Elliott Jin, Franck Chastagnol, Han Lee, Harald Schiöberg, Ivan Traus, Kelly Liu, Michael Mi, Peng Wang, Rajesh Venkataraman, and Sammy Steele.


