


Performance
Index format
Each of the hundreds of our search leaves runs our retrieval engine, whose responsibilities include handling both updating the index when files get created, edited, and deleted (those are “writes”) as well as servicing search queries (these are “reads”). Dropbox traffic has the interesting characteristic that it is dominated by writes—that is, files are updated way more frequently than they are searched for. We typically observe a volume of writes which is 10x higher than reads. As such, we carefully considered those workloads when optimizing the data structures used in the retrieval engine.
A “posting list” is a data structure that maps a token (i.e., a potential search term) to the list of documents containing that token. At its core, a retrieval engine’s primary job is to maintain a set of posting lists which constitute the inverted index. Posting lists are queried during search requests, and updated when updates are applied to the index. A common posting list format stores the token and an associated list of document ids, along with some metadata that can be used during scoring phase (ex: term frequency).

This format is ideal for workloads which are primarily read-only: each search query only requires finding the appropriate set of posting lists (which can be O(1) using a hash table) and then adding each of the associated doc ids to the result set.
However, in order to be able to handle the high update rates we observed in our users’ behavior, we made the decision to use an “exploded” posting list format for the reverse index. Our reverse index is backed by a key/value store (RocksDB) and each (namespace ID, token, document ID) tuple is stored as a separate row. More specifically, the format of the row key is "<namespace ID>|<token>|<doc ID>". Given a search query against documents in a specific namespace, we can efficiently run a prefix search for <namespace ID><token>| in the index to get a list of all matching documents. Having the namespace concept built into the format of the key has several benefits. First and very importantly, in terms of security since it prevents any possibility a query would return documents outside of the specified namespace the user has access to. Second, in terms of performance since it narrows the search to only the documents included in the namespace as opposed to the much larger set of documents indexed in the partition. With this scheme, the value of each row stores the metadata associated with the token.
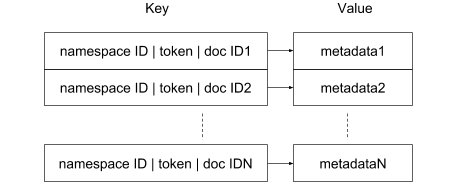
From a storage and retrieval perspective, this is less efficient compared to the more conventional format where all document ids are grouped and can be stored in a compact representation by using techniques such as delta encoding. But the “exploded” representation has the main benefit of handling index mutations particularly efficiently. For example, a document is added to the reverse index by inserting a row for each token it contains—this is a simple operation that performs very efficiently on most key/value stores, including RocksDB. The extra storage penalty is alleviated by the fact that RocksDB applies prefix compression of keys—overall we found the index size using an exploded representation was only about 15% larger compared to one using a conventional posting list representation.
Serving
Responsive performance is critical to a smooth and interactive user experience. The primary metric we use for evaluating serving performance is query latency at 95th and 99th percentile, i.e., the slowest 5% and 1% of queries should be no slower than 500ms and 1sec, respectively (currently). The median query will, of course, be significantly faster. As the development of the Nautilus system progressed, we continuously measured and analyzed performance. Each component of the system is instrumented in order to be able to determine how much it contributes to the overall latency. We learned a few lessons along the way, including:
- Do not prematurely optimize: We refrained from improving the retrieval engine performance until we understood how every component of the system contributed to overall latency. One might have expected the bulk of the time to be spent in the retrieval phase; but after an initial analysis of the data, we determined that a significant portion of the latency actually came from fetching metadata from external systems—backed by relational databases—for checking ACLs and “decorating” the search results before returning them. This includes things like listing the folder path, creator, last modified time, etc.
- Fear the “query of death”: Overall latency can be very adversely impacted by a few harmful queries, sometime referred to as “queries of death.” These usually result from errors in software that programmatically hits the search API, rather than human users. We built circuit breakers that filter out those queries in order to protect the overall system. In addition, we implemented the ability to respect a “time budget”—where the retrieval engine stops fetching candidates for a query once its allocated time budget is exceeded. We found that this helps performance and the overall system load, but at the cost of sometimes not returning all possible results. This mostly happens for very broad queries that match many candidates—for example when doing prefix search on a single token (as happens during the auto-completion of search queries).
- Replicas can help with tail latency too: Our leaves are replicated 2X for redundancy in case the machine runs into problems. However, these replicas have a performance benefit as well: they can be used for improving tail latency (the latency of the slowest requests). We use the well-known technique of sending a query to all replicas and returning the response from the fastest one.
- Invest in building benchmarking tools: Once a specific component is identified as a performance bottleneck, writing a benchmarking tool to load test and measure performance of that specific component is a better way to iterate quickly on improving performances than testing the whole system. In our case, we wrote a benchmark tool for the core retrieval engine which runs on the leaves. We use it to measure the engine’s indexing and retrieval performance at the partition level against synthetic data. The partition data is generated to have characteristics close to production in terms of overall number of namespaces, documents, tokens, as well as distribution of number of documents per namespace, and number of tokens per document.
Reliability
Millions of users rely on Dropbox search in order to perform their work, so we paid special attention when designing the system to ensure that we could guarantee the uptime our users expect.
In a large distributed system, network or hardware failures and software crashes happen regularly—they are inevitable. We kept this fact in mind when we designed Nautilus, focusing particularly on fault-tolerance and automatic recovery for components in the serving path.
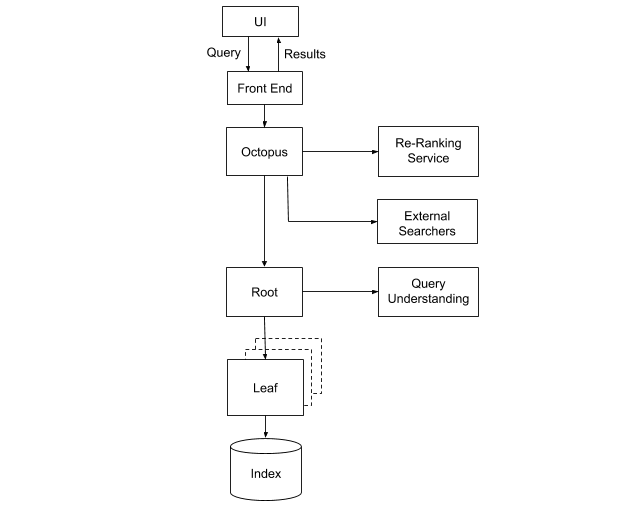
Some of the components were designed to be stateless, meaning that they rely on no external services or data to operate. This includes Octopus, our results merging and ranking system; and the root of the retrieval engine, which fans out search requests to all the leaves. These services can thus be easily deployed with multiple instances, each of which can be automatically reprovisioned as failures occur. The problem is more challenging when it comes to the leaves instances, since they maintain the index data.
Partition assignment
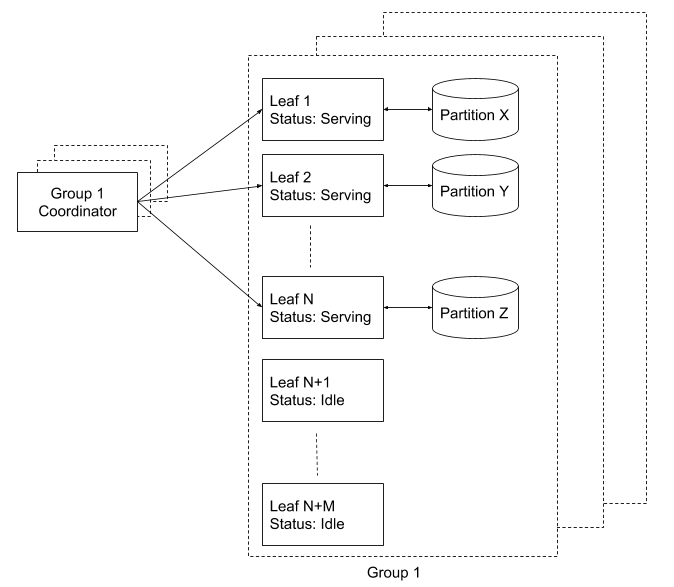
In Nautilus, each leaf instance is responsible for handling a subset of the search index, called a “partition.” We maintain a registry of all leaves and assign partitions to the leaves using a separate coordinator. The coordinator is responsible for ensuring continuous coverage for 100% of the partitions. When a new leaf instance is brought up, it stays idle until instructed by the coordinator to serve a partition, at which point it loads the index and then starts accepting search requests.
What happens if a leaf is in the process of coming online, but there is a search request for data in its partition? We deal with this by maintaining replicas of each leaf, which together are called “leaf replica groups.” A replica group is an independent cluster of leaf instances providing full coverage of the index. For example, to ensure 2X replication for the system, we run two replica groups, with one coordinator per group. In addition to making it simple to reason about replication, this setup provides operational benefits for doing maintenance, such as:
- New code can be rolled out to production without any availability-impact by simply deploying it to one group after another.
- An entire group can be added or removed. This is particularly handy for doing hardware or OS upgrades. For example, a group running on new hardware can be added, and once it is fully operational, we can then decommission the group running on the older hardware.
In both of these cases, Nautilus is fully able to answer all requests throughout the entire process.
Recovery
Each leaf group is over-provisioned with about 15% extra hardware capacity to have a pool of idle instances standing by. When the coordinator detects a drop in partition coverage (i.e., say a currently active leaf suddenly stops serving requests), it reacts by picking an idle leaf and instructing it to serve the lost partition. That leaf then performs the following steps:
- Download the index data associated with the partition from the index repository. This provides the leaf with a stale index since it was generated some time ago by the offline build system.
- Replay old mutations from the Kafka queue starting at the offset corresponding to when the index partition was built.
- Once these older mutations have finished being applied on top of the downloaded index, it means the leaf index is up to date. At that point the leaf goes into serving mode and starts processing queries.
Nautilus is a prime example of the type of large scale projects involving data retrieval and machine learning that engineers at Dropbox tackle. If you are interested in these kinds of problems, we would love to have you on our team.
Thanks to: Adam Faulkner, Adhiraj Somani, Alan Shieh, Annie Zhou, Braeden Kepner, Elliott Jin, Franck Chastagnol, Han Lee, Harald Schiöberg, Ivan Traus, Kelly Liu, Michael Mi, Peng Wang, Rajesh Venkataraman, and Sammy Steele.


