

One of the greatest challenges associated with maintaining a complex desktop application like Dropbox is that with hundreds of millions of installs, even the smallest bugs can end up affecting a very large number of users. Bugs inevitably will strike, and while most of them allow the application to recover, some cause the application to terminate. These terminations, or “crashes,” are highly disruptive events: when Dropbox stops, synchronization stops. To ensure uninterrupted sync for our users we automatically detect and report all crashes and take steps to restart our application when they occur.
In 2016, faced with our impending transition to Python 3, we set out to revamp how we detect and report crashes. Today, our crash reporting pipeline is a reliable cornerstone for our desktop teams, both in volume and quality of reports. In this post, we’ll dive into how we designed this new system.
Python doesn’t crash, right?
Dropbox is partly written in Python, and while it certainly is a safe, high-level language, it is not immune to crashes. Most crashes (i.e. unhandled exceptions) are simple to deal with because they occur in Python, but many originate “below”: in non-Python code, within the interpreter code itself, or within Python extensions. These “native” crashes, as we refer to them, are nothing new: improper memory manipulation, for example, has plagued developers for decades.
As our application grew more complex, we began to rely on other programming languages to build some of our features. This was particularly true when integrating with the operating system, where the easiest path tends to lead to platform-specific tooling and languages (e.g. COM on Windows and Objective-C on macOS). This has led to an increased share of non-Python code in our codebase, which has brought along an increased risk for dangling pointers, memory errors, data races, and unchecked array accesses: all of which can cause Dropbox to be unceremoniously terminated. As a result, a single crash report can now contain Python, C++, Objective-C, and C code in its stack trace!
The Early Days
For several years, we relied on a simple in-process crash detection mechanism: a signal handler. This scheme allowed us to “trap” various UNIX signals (and on Windows, their analogues). Upon hitting a fatal signal (i.e. SIGFPE), our signal handler would attempt to:
- Capture the Python stack trace (using the
faulthandlermodule) for each thread - Capture the native stack trace for that thread (typically using
libc'sbacktraceandbacktrace_symbolsfunctions)
We would then attempt to securely upload this data to Dropbox’s servers.
While this was adequate, a few fundamental issues affected reliability or limited its usefulness in debugging:
- If a problem occurred before we set up the handler, we wouldn’t get any reports. This is usually caused by an
ImportError, a missing library, or an installation error. These fundamental “boot errors” are the most severe because they result in the user being unable to start the app. We were unable to capture these at all, an unacceptable situation. The only way for any reports of these issues to reach our engineers was by contacting customer support. While we built a helpful error dialog to help with this process, this still led to our team becoming somewhat risk-averse to meddling with startup/early code. - The signal handler is somewhat fragile. This handler was responsible for not only capturing state but also sending it to our servers. Over time, we realized it could often fail to send the report despite managing to generate it successfully. In addition, particularly severe crashes could make it impossible to correctly extract state on a crash. For example, if the interpreter state itself became corrupted, it could prevent us from including the Python stack trace—or worse, could derail the entire handling process.
One of the root causes of this is the nature of signal handling itself: while, thankfully, Python’s signal module takes care of most these, it also adds its own restrictions. For example, signals can only be called from the main thread and may not be run synchronously. This asynchronicity meant that some of the most common SIGSEGVs could often fail to be trapped from Python! 1
Crashpad to the rescue
A more reliable crash reporting mechanism can be built by extracting the reporter outside of the main process. This is readily feasible, as both Windows and MacOS provide system facilities to trap out-of-process crashes. The Chromium project has developed a comprehensive crash capture/report solution that leverages this functionality and that can be used as a standalone library: Crashpad.
Crashpad is deployed as a small helper process that monitors your application, waits for a signal that it has crashed, and then captures useful information, including:
- The reason a process crashed and the thread that originated the crash
- Stack traces for all threads
- Contents of parts of the heap
- Extra annotations that developers can add to their application (a useful layer of flexibility)
All of this is captured in a minidump payload, a Microsoft-authored format originally used on Windows and somewhat similar to a Unix-style core dump. The format is openly documented, and there exists excellent server-side tooling (again, mainly from Google and Mozilla) to process such data.
The following diagram outlines Crashpad’s basic architecture:
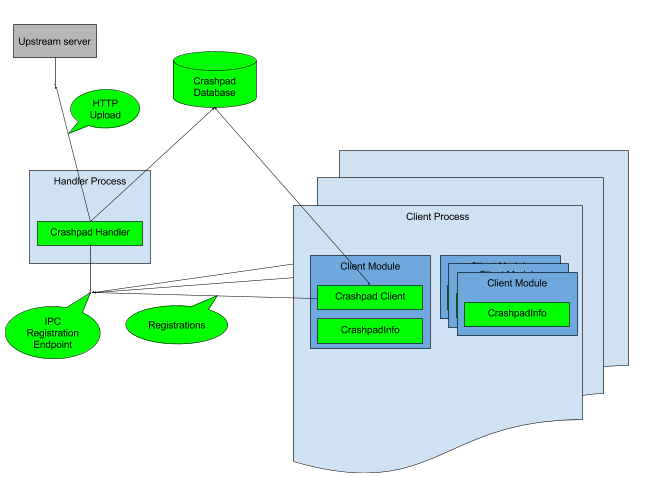
An application uses Crashpad by instantiating an in-process object—called the “client”—that reports to an out-of-process helper—called a “handler”—when it detects a crash.
We decided to use this library to mitigate many of the reliability issues associated with an in-process signal handler. This was an easy choice due to its use by Chromium, one of the most popular desktop applications ever released. We were also enthused by more sophisticated support for Windows, a rather different platform from UNIX. faulthandler was (at the time) limited in its support for Windows-specific crashes, since it was very much based on signals, a UNIX/POSIX concept. Crashpad leverages Structured Exception Handling (or SEH), allowing it to catch a much broader range of fatal Windows-specific exceptions.
A note on Linux: Though Linux support has been very recently introduced, Crashpad was only available for Windows and MacOS when we first deployed it, so we limited our use of the library to these platforms. On Linux, we continue to use the in-process signal handler, though we will re-visit this in the future.
Symbolication
Dropbox, like most compiled applications, ships to users in a “Release” configuration, where several compiler optimizations are enabled and symbols are stripped to reduce binary size. This means the information gathered is mostly useless unless it can be “mapped” back to source code. This is referred to as “symbolication”.
To achieve this, we preserve symbols for each Dropbox build on internal servers. This is a core part of our build process: symbol generation failure is considered a build failure, making it impossible for us to release a build that cannot later be symbolicated.
When a minidump is received as part of a crash report, we use the symbols for the build to decipher each stack trace and link it back to source code. When system libraries are used, we defer to platform-specific symbols. This process allows our developers to quickly find where crashes originate in either first or third-party code.
Microsoft maintains public symbol servers for all Windows builds in order for stack frames involving their functions to be mapped. Unfortunately, Apple does not have a similar system: instead, the platform’s frameworks include their matching symbols. To support this, we currently cache the symbols of various macOS frameworks (for a wide range of OS versions) using our testing VMs (though we can still occasionally end up with gaps in our coverage).
A validation sidecar
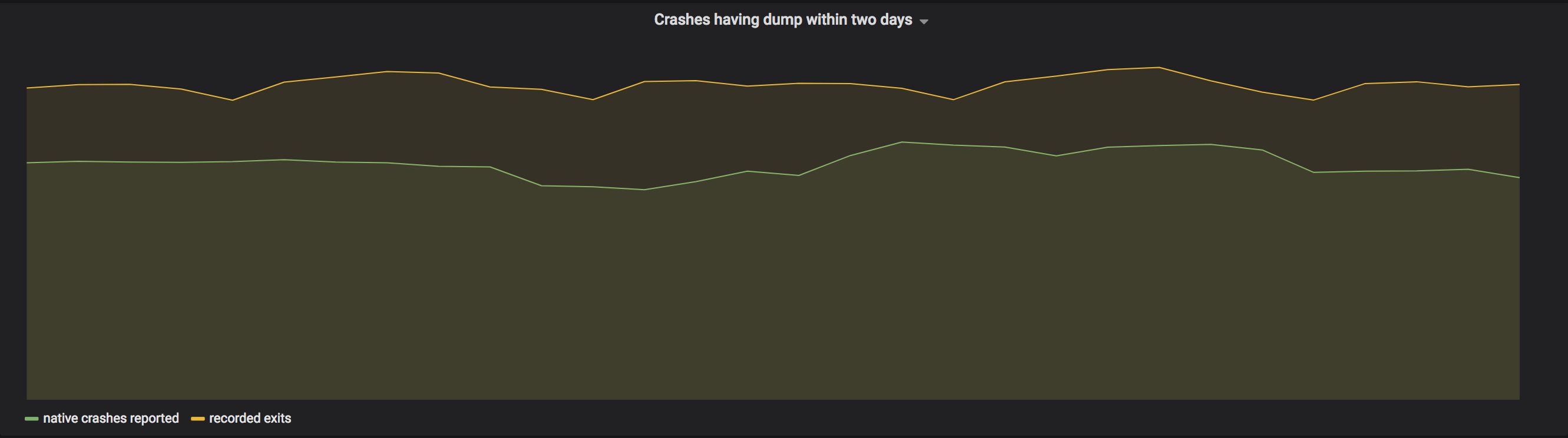
Changing our crash reporting infrastructure from underneath millions of installations was a risky endeavor: we required validation that our new mechanism was working. It’s also important to note that not all terminations are necessarily crashes (e.g. the user closing the app or an automatic update). That being said, some terminations may still indicate problems. We therefore wanted a way to record and classify exits along with crashes. This also would provide us with a baseline to validate that our new crash reporter was capturing a high fraction of total crashes.
To address this, we built yet another “sidecar” process we named “watchdog.” This is another small “companion” process (similar to Crashpad) that has a single responsibility: when the desktop app exits, it captures its exit status to determine whether it was “successful” (that is, a user or app-initiated shutdown instead of being forcibly terminated). This process is extremely simple by intention as we want it to be highly reliable.
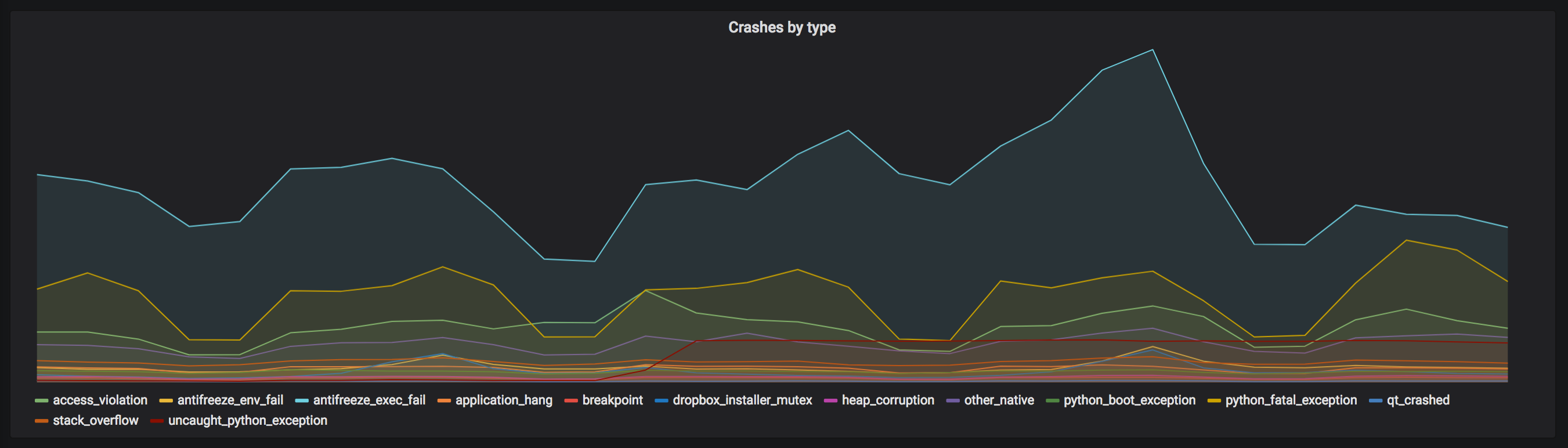
To provide a basis for comparison, a start event is generated by making our application send an event on launch. With both start and exit events, we are then able to measure the accuracy of exit monitoring itself: we can ensure it was successful for a very high percentage of our users (note that firewalls, corporate policies, and other programs prevent this from working 100% of the time). In addition, we can now match this exit event against crashes coming from Crashpad to make sure that exit codes in which we expect crashes indeed include crash reports from most users. The graphs below show the monitoring we have in place:
We wrote the watchdog process in Rust, which we chose for a variety of reasons:
- The safety guarantees offered by the language make it a lot easier to trust code.
- The operating system abstractions are well designed, part of the standard library, and easy to extend via FFI wherever required.
- We have developed quite a bit of Rust expertise at Dropbox, giving this project an easier ramp-up.
Teaching Crashpad about Python
Crashpad was primarily designed for native code, as Chromium is mostly written in C++. However, the Dropbox client is mostly written in Python. As Python is an interpreted language, most native crash reports we receive thus tend to look like this:
0 _ctypes.cpython-35m-darwin.so!_i_get + 0x4
1 _ctypes.cpython-35m-darwin.so!_Simple_repr + 0x4a
2 libdropbox_python.3.5.dylib!_PyObject_Str + 0x8e
3 libdropbox_python.3.5.dylib!_PyFile_WriteObject + 0x79
4 libdropbox_python.3.5.dylib!_builtin_print + 0x1dc
5 libdropbox_python.3.5.dylib!_PyCFunction_Call + 0x7a
6 libdropbox_python.3.5.dylib!_PyEval_EvalFrameEx + 0x5f12
7 libdropbox_python.3.5.dylib!_fast_function + 0x19d
8 libdropbox_python.3.5.dylib!_PyEval_EvalFrameEx + 0x5770
9 libdropbox_python.3.5.dylib!__PyEval_EvalCodeWithName + 0xc9e
10 libdropbox_python.3.5.dylib!_PyEval_EvalCodeEx + 0x24
11 libdropbox_python.3.5.dylib!_function_call + 0x16f
12 libdropbox_python.3.5.dylib!_PyObject_Call + 0x65
13 libdropbox_python.3.5.dylib!_PyEval_EvalFrameEx + 0x666a
14 libdropbox_python.3.5.dylib!__PyEval_EvalCodeWithName + 0xc9e
15 libdropbox_python.3.5.dylib!_PyEval_EvalCodeEx + 0x24
16 libdropbox_python.3.5.dylib!_function_call + 0x16f
17 libdropbox_python.3.5.dylib!_PyObject_Call + 0x65
18 libdropbox_python.3.5.dylib!_PyEval_EvalFrameEx + 0x666a
19 libdropbox_python.3.5.dylib!__PyEval_EvalCodeWithName + 0xc9e
20 libdropbox_python.3.5.dylib!_PyEval_EvalCodeEx + 0x24
21 libdropbox_python.3.5.dylib!_function_call + 0x16f
22 libdropbox_python.3.5.dylib!_PyObject_Call + 0x65
... on and onThis stack trace is not very helpful to a developer trying to discover the cause of a crash. Whereas faulthandler also included the Python stack frames of all threads, Crashpad does not have this ability by default. To make this report useful, we would need to include the relevant Python state. However, as Crashpad is not written in Python and is out-of-process, we don’t have access to faulthandler itself: how might we go about doing this?
When the crashing program is suspended, all of its memory is available to Crashpad, which can read it to capture the program state. As the program is potentially in a bad state, we can’t execute any code within it. Instead we need to:
- Figure out where the Python data structures are laid out in memory
- Walk the relevant data structures to figure out what code was running when the program crashed
- Store this information and securely upload it to our servers
We chose Crashpad in part for its customizability: it is fairly easy to extend. We therefore added code to the ProcessSnapshot class to capture Python stacks, and introduced our own custom minidump “stream” (supported by both the file format and Crashpad itself) to persist and report this information.
Python and Thread-Local Storage
First, we needed to know where to look. In CPython, interpreter threads are always backed by native threads. Therefore, in the Dropbox application, each native thread created by Python has an associated PyThreadState structure. The interpreter uses native thread-specific storage to create the connection between this object and the native thread. As Crashpad has access to the monitored process’ memory, it can read this state and include it as part of a report.
As Dropbox ships a customized fork of CPython, we have effective control over its behavior. This means that not only can we use this knowledge to our advantage but we can rely on it knowing it won’t easily change from under us.
In Python, thread-specific storage is implemented in platform-specific ways:
- On POSIX, pthread_key_create is used to allocate the key, while pthread_(get/set)specific are used to interact with them
- On Windows, TlsAlloc is used to allocate thread-local “slots” stored in a predictable/documented location in the Thread Environment Block.aspx)
- Note: We contributed fixes to Crashpad to make this readily available
Common to all platforms, however, is that the Python-specific state is stored at a specific offset of the native thread state. Sadly, this offset is not static: it can change depending on various factors. This offset is determined early in the Python runtime’s setup (see PyInitialize): this is referred to as the thread-specific storage “key”. This step creates a single “slot” of thread-specific storage for all threads in the process, which is then used by Python to store its thread-specific state.
So if crashpad can retrieve the TSS “key” for the instance of the process, it will have the ability to read the PyThreadState for any given thread.
Getting the Thread-Local Storage “Key”
We considered multiple ways of doing this, but settled on a method inspired by Crashpad itself. In the end, we modified our fork of Python to expose the runtime state (including the TSS key) in a named section of the binary (i.e. __DATA). Thus, all instances of Dropbox would now expose the Python runtime state in a way that makes it easy to retrieve it from Crashpad.
- This was achieved with a simple __attribute__ in Clang and by using __declspec on Windows.
- This is already simple to use in Crashpad, because it uses the same technique to allow clients to add annotations to their own process (see CrashpadInfo).
- This is also well-aligned with Python’s own evolving design for the interpreter internals, as it recently reorganized itself to consolidate runtime state into a single struct, _PyRuntime (in Python/pylifecycle.c). This structure includes the TSS key, along with other information of potential interest to debug tools.
- Note: We’ve submitted this change as a pull request to the Python project, in case it can be helpful to others.
Now that Crashpad can determine the TSS key, it has access to each thread’s PyThreadState. The next step is to interpret this state, extract the relevant information, and send it as part of a crash report.
Parsing Python Stack Frames
In CPython, “frames” are the unit of function execution, and the Python analogue to native stack frames. The PyThreadState maintains them as a stack of PyFrameObjects. The topmost frame at any given time is pointed to by the thread state using a single pointer. Given this setup and the TSS key, we can start from a native thread, find the PyThreadState, then “walk the stack” of PyFrameObjects.
However, this is trickier than it sounds. We can’t just #include <Python.h> and call the same functions faulthandler does: as Crashpad’s handler runs in a separate process, it doesn’t have direct access to this state. Instead, we had to use Crashpad’s utilities to reach into the crashing process’s memory and maintain our own “copies” of the relevant Python structs to interpret the raw data. This is a necessarily brittle solution, but we’ve mitigated the cost of ongoing maintenance by introducing automated tests that ensure that any updates to Python’s core structs to also require an update our Crashpad fork.
For every frame, our objective is to resolve it to a code location. Each PyFrameObject has a pointer to a PyCodeObject including information about the function name, file name, and line number (faulthandler leverages the same information).
The filename and function name are maintained as Python strings. Decoding Python strings can be fairly involved, as they are built on a hierarchy of types (we’ll spare you the details, but see unicodeobject.h). For simplicity, we assume all function and file names are ASCII-encoded (mapping to the simple PyASCIIObject).
Getting the line number is slightly more complicated. To save space, while being able to map every byte code instruction to Python source, Python compresses line numbers into a table (PyCodeObject‘s co_lnotab). The algorithm to decode this table is well-defined, so we re-implemented it in our Crashpad fork.
A note on the Python 3 transition: As Python 2 and 3 have slightly different implementations, we maintained support for both versions of the Python structs in our Crashpad fork during the transition.
Stack Frame Reconstitution
Now that Crashpad’s reports include all the Python stack frames, we can improve symbolication. To do so, we modified our server infrastructure to parse our extensions to minidumps and extract these stacks. Specifically, we augmented our crash management system, Crashdash, to display Python stack frame information (if it is available) for native crash reports.
This is achieved by “walking the stack” again, but this time, for each native frame calling PyEval_EvalFrameEx, we “pop” the matching PyFrameObject capture from the report. Since we now have the function name, file name, and line number for each of those frames we can now show the matching function calls. We can thus extract the underlying Python stack trace from the one above:
file "ui/common/tray.py", line 758, in _do_segfault
file "dropbox/client/ui/cocoa/menu.py", line 169, in menuAction_
file "dropbox/gui.py", line 274, in guarantee_message_queue
file "dropbox/gui.py", line 299, in handle_exceptions
file "PyObjCTools/AppHelper.py", line 303, in runEventLoop
file "ui/cocoa/uikit.py", line 256, in mainloop
file "ui/cocoa/uikit.py", line 929, in mainloop
file "dropbox/client/main.py", line 3263, in run
file "dropbox/client/main.py", line 6904, in main_startup
file "dropbox/client/main.py", line 7000, in mainWrapping up
With this system in place, our developers are capable of directly investigating all crashes, whether they occur in Python, C, C++, or Objective-C. In addition, the new monitoring we introduced to measure the system’s reliability has given us added confidence our application is performing as it should. The result is a more stable application for our desktop users. Case in point: using this new system, we were able to perform the Python 2 to 3 transition without fear that our users would be negatively affected.
Nikhil gave a talk at PyGotham 2018 that dives into Python stack frame implementation details and explains our strategy for using Crashpad. The slides are available now (videos will be up soon).
Interested? If the type of problem solving we described sounds fun and you want to take on the challenges of desktop Python development at scale, consider joining us!
Footnotes:
1 A SIGSEGV cannot be handled asynchronously due to how signals are implemented. When a CPU instruction attempts to access an invalid location, it triggers a page fault. This is handled by the OS. The OS will first rewind the instruction pointer to go back to the beginning of this instruction, since it needs to resume execution of the program once the signal handler returns. The first time, the signal handler is triggered. Once it returns, execution resumes. The OS tracks that a handler was already invoked. When the fault is triggered again, this specific signal is masked so that no handler runs. At this point, the behavior for a SIGSEGV is to core dump the process and abort it. Our asynchronous handler effectively never runs. The faulthandler module specifically supports synchronous capture of Python stacks, but it can only save these to a file. No network activity or Python execution is allowed due to signal safety requirements. These various complications, and the clear benefits of Crashpad in other areas, made it compelling to switch.


