

Dropbox stores petabytes of metadata to support user-facing features and to power our production infrastructure. The primary system we use to store this metadata is named Edgestore and is described in a previous blog post, (Re)Introducing Edgestore. In simple terms, Edgestore is a service and abstraction over thousands of MySQL nodes that provides users with strongly consistent, transactional reads and writes at low latency.
Edgestore hides details of physical sharding from the application layer to allow developers to scale out their metadata storage needs without thinking about complexities of data placement and distribution. Central to building a distributed database on top of individual MySQL shards in Edgestore is the ability to collocate related data items together on the same shard. Developers express logical collocation of data via the concept of a colo, indicating that two pieces of data are typically accessed together. In turn, Edgestore provides low-latency, transactional guarantees for reads and writes within a given colo (by placing them on the same physical MySQL shard), but only best-effort support across colos.
While the product use-cases at Dropbox are usually a good fit for collocation, over time we found that certain ones just aren’t easily partitionable. As a simple example, an association between a user and the content they share with another user is unlikely to be collocated, since the users likely live on different shards. Even if we were to attempt to reorganize physical storage such that related colos land on the same physical shards, we would never get a perfect cut of data.
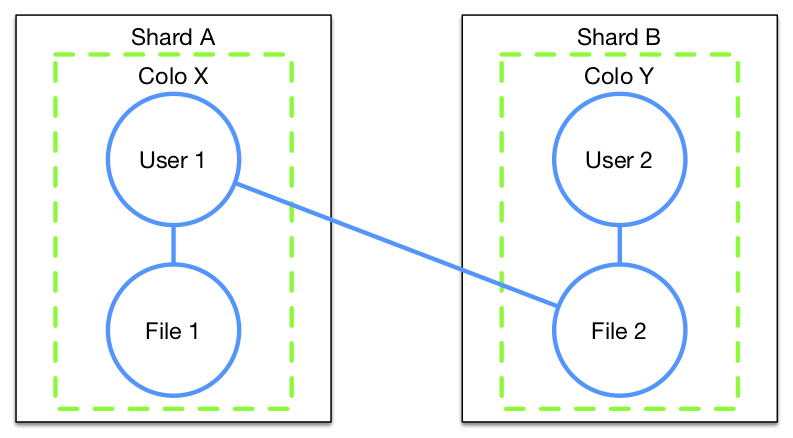
For data that was not easily collocatable, developers were forced to implement application-level primitives to mask over a lack of cross-shard transactionality, slowing down application development and incurring an unnecessary technical burden. This blog post focuses on our recent deployment of cross shard transactions, which addressed this deficiency in Edgestore’s API, allowing atomic transactions across colos. What follows is a description of our design, potential pitfalls one may encounter along the way, and how we safely validated and deployed this new feature to a live application serving more than ten million requests per second.
Two-phase commit
The standard protocol for executing a transaction across database shards is two-phase commit, which has existed since at least the 1970s. We applied a modified version of this protocol to support cross-shard transactions in Edgestore.
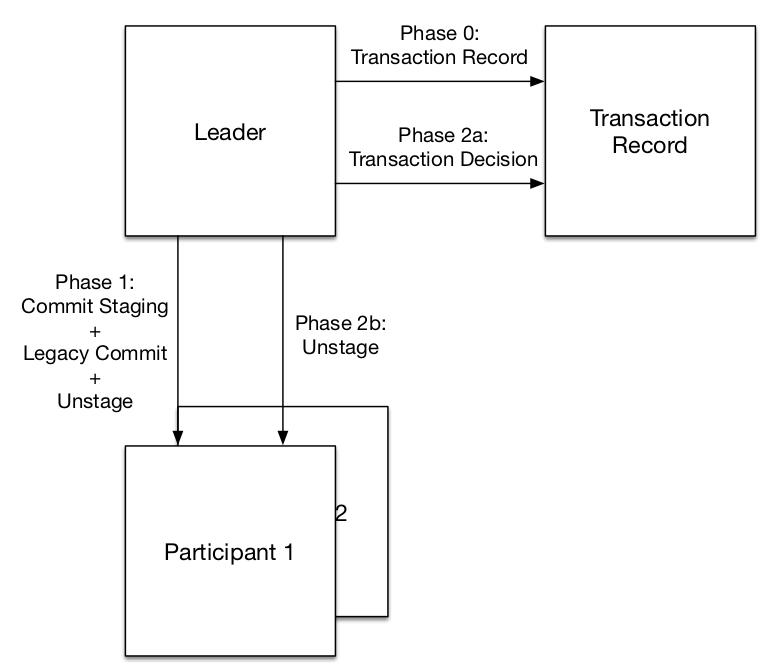
Two-phase commit requires a leader to execute a transaction across multiple participants, in our case Edgestore shards. The protocol works as follows:

Phase 0: Transaction Record
- Leader writes a durable transaction record indicating that a cross-shard transaction is about to happen.
The addition of an external transaction record to serve as a source of truth about the state of a transaction is the main way in which our protocol differs from standard two-phase commit. This phase isn’t required in the standard protocol but provides both performance and correctness benefits in our use-case, which we’ll describe below.
After writing the transaction record, the protocol follows its traditional path:
Phase 1: Commit Staging
- All participants write a durable record that they are willing to commit the transaction and then notify the leader of their intent to commit.
At this point the participants have indicated that they are willing to commit the transaction, but they don’t yet know if the leader has decided to commit it or not. To ensure correctness they must ensure that no other concurrent transactions can observe state that conflicts with the ultimate commit or abort decision made by the leader; we’ll refer to this below as filtering.
Phase 2a: Transaction Decision
- After receiving a response from all participants, the leader updates the durable transaction record to signify that the transaction is committed. (If it doesn’t receive a response from all participants it can instead mark the transaction as aborted.)
Like Phase 0, Phase 2a is not strictly required by the two-phase commit protocol but makes the commit point explicit. This means that even if all participants agree to the transaction and stage the mutations, the transaction is not considered committed until the transaction record is updated to reflect that. In consequence, any parallel operation can abort a transaction at any time up until the transaction record leaves its pending state, which makes recovery in the case of leader failure straightforward (just abort and move on, instead of contacting all participants and entering a recovery procedure) and improves the liveness of the system under error conditions. It also makes filtering straightforward—a concurrent read or write need only contact the node containing the transaction record to determine transaction state, which improves performance for latency-sensitive clients.
The protocol completes with one final step:
Phase 2b: Commit Application
- The leader notifies the participants of the commit decision and they can make the new state visible. (They will delete the staged state if the leader has aborted the transaction.)
Making two-phase commit practical
Two-phase commit is a relatively simple protocol in theory, but unfortunately there are a lot of practical barriers to implementing it. One key problem is read and write amplification: an increase in the number of reads and writes in the protocol path. Write amplification is inherent in the fact that not only do you need to write a transaction record, but also you need to durably stage a commit, which incurs at least one additional write per participant. The extra writes increase the critical section of the transaction, which can cause lock contention and application instability. Moreover, on every read, the database also needs to perform filtering to ensure that the read doesn’t observe any state that is dependent on a pending cross-shard transaction, which affects all reads in the system, even non-transactional ones.
Therefore, in order to translate two-phase commit to Edgestore, we needed a design that answered three questions:
- How to efficiently determine transaction state.
- How to mitigate the performance penalty of staging and applying commits.
- How to minimize the filtering penalty for reads.
External transaction record
As mentioned in the previous section introducing two-phase commit, we found that modifying the two-phase commit protocol to utilize an external transaction record minimized the performance cost of determining transaction state, since a concurrent request need only check the transaction record to determine the state of the transaction as opposed to contacting each of the participants. By extension, this limits the worst-case filtering penalty for reads, since they will need to contact at most two nodes—the local participant and the (possibly local) node storing the transaction record. We implemented the transaction record as an Edgestore object, which gave us all the original strong consistency guarantees of single-colo operations and allowed us to collocate the transaction record with one of the cross-shard transaction participants.
Copy-on-write
A typical approach to implementing commit staging would be to store a fully materialized copy of the staged data alongside the existing data as in a multiversioned storage system. However, Edgestore’s underlying MySQL schema doesn’t support storing duplicates of a given object. Therefore, an approach where we write a full copy of an object to a secondary MySQL table to stage a commit and copy it into the primary data table to apply it would have the effect of doubling the cost (and latency) of every transaction.
Instead, we chose to implement commit staging and application using copy-on-write. In order to stage a commit, we commit the raw mutations in a separate MySQL table, and then only on commit application do we materialize the transaction and apply the state to the primary data tables. By taking this approach, we reduced our write amplification by up to 95% over a naive multiversioning approach.

Additionally, our copy-on-write implementation provided significant performance benefits for readers. In steady state, any given record is not likely to have an in-flight mutation, and the size of the secondary MySQL table should be roughly proportional to the rate of cross-shard transactions. This means that the typical filtering cost to a reader is simply the cost of a local existence check against a table that is small enough to fit in memory, after which point it can serve the read from the same node. If there is a staged commit, then it must either wait for or assist the application of the in-flight transaction, which involves contacting at most one other node.
Deploying to a live system
Of course, it’s one thing to have a design for a system you believe is correct but entirely another to prove it. Since Edgestore has been running for years and backs almost every request to Dropbox, the design itself had to accommodate validating our assumptions about consistency, correctness, and performance while providing a path for safe rollout.
This was the fun part 😛
Offline consistency harness
The whole purpose of the project was to offer an Edgestore API with enhanced consistency. Therefore, we needed to prove to ourselves beyond a doubt that our implementation upheld the newly stated guarantees. To do this, we built an offline test harness that we ran continuously in our build environment (amounting to multiple years of CPU time) to corroborate our assertions: cross shard transactions in Edgestore are atomic and strictly serializable.
The basic theory behind the test harness is that given a full history of all mutations, you can construct a precedence graph describing ordering relationships among the transactions responsible for those mutations. You construct a precedence graph by writing a node for each transaction, and then connecting it to another transaction with a directed edge if it performs an operation on shared data before that other transaction. The topological ordering defined by this graph describes the valid serial orderings of transactions, and therefore the graph should be acyclic. If it has a cycle, you have violated serializability.
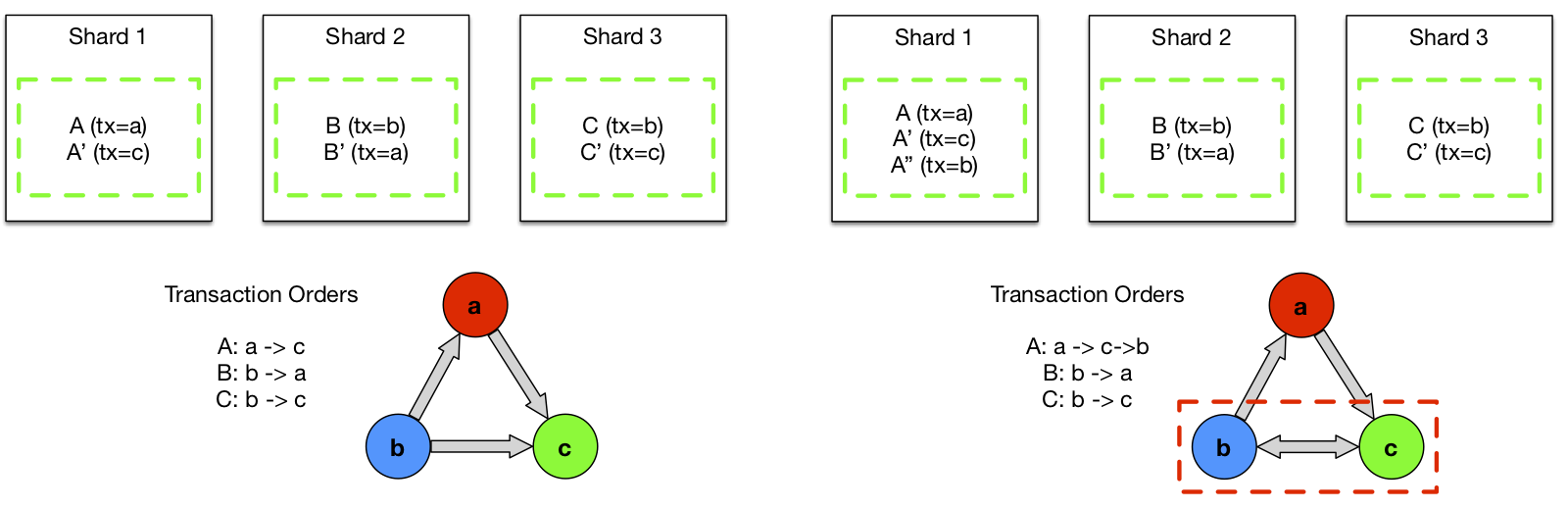
Taking the concept one step further, if you replace the transaction nodes with nodes representing each participant of the transaction, you can use the resulting graph to prove atomicity. Roughly, if the mutations applied to each participant also embed information about other participants (directed edges radiating outward from a node representing the participant), the subgraph formed by connecting each participant’s view of the mutation set should form a complete, directed graph (each complete subgraph can be identified with a transaction node in the precedence graph). If there are missing or dangling edges, you have violated atomicity.
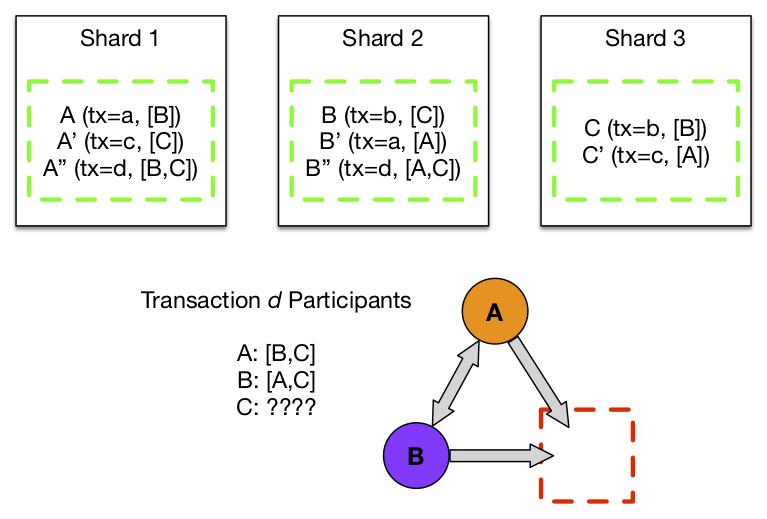
To build our harness, we created special Edgestore objects with two fields: one for the transaction identifier (which we filled by introspecting our RPC headers) to provide the directed edges for our precedence graph, and the other for the expected participant list. We then wrote a client that issues transactions on random subsets of the objects, updating the two fields as appropriate. We enabled application-level multiversioning so we could later recover the full mutation history, and we added random fault injection to increase coverage of error paths. (A careful reader will observe that we are missing the strict portion of strict serializability guarantee—we added some read-only threads with extra logic to handle this).
In the end, the harness surfaced multiple bugs, one as basic as a dropped error, and another as subtle as a flaw in the read filtering protocol. These bugs would have been nearly impossible to detect, let alone root-cause, had they occurred outside of a simulated environment. That may seem like a small payoff for multiple CPU-years of testing, but for us and our users, it was worth every minute.
Production shadowing
In parallel with consistency verification, we also set out to validate the two other pieces of our design: the correctness of our copy-on-write implementation, and the performance cost of our two-phase commit design when inlined into the existing system. The first was a potential risk because if the materialization logic was wrong or the stored mutation did not fully encode user-facing write APIs, we could end up in a state where commit application would not know how to properly apply the transaction. The second was critical for the continued reliability of Edgestore—any drastic change in latency, traffic, or locking could cause system instability and break upstream applications.
During the design phase for cross-shard transactions, we realized we could achieve both of these goals by introducing a modified two-phase commit protocol. In the “validation” version of the protocol, the commit staging phase would perform the shadow write, and then immediately delete the “staged” commit as part of the transaction generated by the existing Edgestore API, all without communicating back to the leader. In turn, a truncated commit application phase would no-op without attempting to recreate the transaction, since the data had already been written and the commit unstaged. Filtering, similarly, would always check for shadow transactions but ignore the result, since the transaction would have already been committed.
The modified protocol preserved the existing API and was resilient to a bug in the shadow representation, since the original API writes remained the source of truth instead of a transaction reconstructed from a potentially incorrect shadow. Moreover, while the transaction semantics were unchanged from the perspective of Edgestore clients, Edgestore itself operated under the expected extra coordination and load from a two-phase commit. We thus validated our performance assumptions with very little risk, since we could increase the amount of traffic doing this pseudo-two-phase commit in a controlled manner.
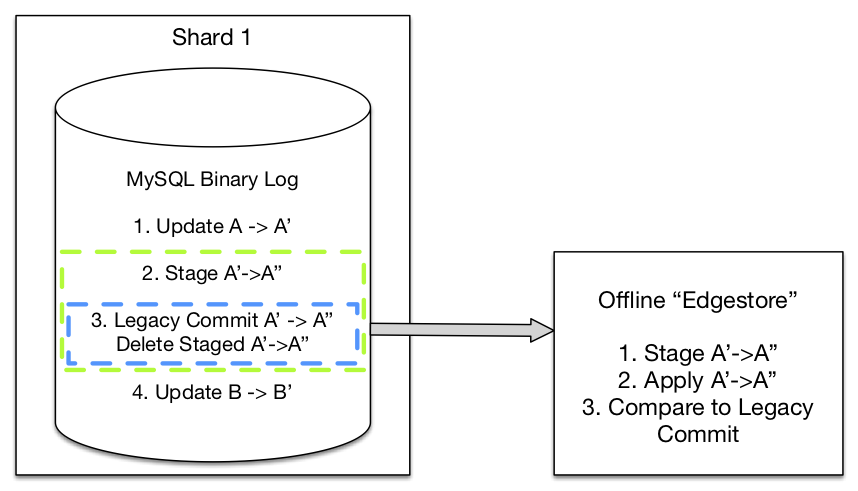
The “validation” two-phase commit also provided a straightforward way of corroborating the correctness of the shadow representation. Since the modified commit staging wrote a MySQL transaction with both the original API result and the shadow representation, we could extract the two atomically from the MySQL binary log and try converting between the two. If our conversion logic produced a different result from the shadow than the actually committed data, we would know there was a bug. This enabled us to identify a few features of our existing API that would have been incompatible with cross shard transactions and allowed us to proactively address the gaps before going live with the new protocol.
Limitations
Although two-phase commit was a fairly natural fit for Edgestore’s existing workload, it is not a silver bullet for those looking to improve their consistency guarantees. Edgestore data was already well-collocated, which meant that cross-shard transactions ended up being fairly rare in practice—only 5-10% of Edgestore transactions involve multiple shards. Had this not been the case, upstream applications might not have been able to handle the increased latency and lock contention that comes with two-phase commit. Moreover, in many cases cross shard transactions replaced more expensive, application-level protocols, which meant the change was a net win for performance in addition to simplifying developer logic.
Two-phase commit in Edgestore also benefits from a strongly-consistent caching layer that absorbs upwards of 95% of client reads. This significantly cuts down on the read filtering penalty, which might have been otherwise untenable. Systems without an auxiliary cache or those optimized for simpler write patterns might similarly find two-phase commit unwieldy and prefer to opt for storage-level multiversioning or consistency abstractions provided as intermediary service layers between clients and the storage engine. This is a direction we are exploring for our next-generation metadata storage—combining a simple, key-value storage primitive and then building a suite of metadata services on top with varying levels of consistency and developer control. Stay tuned for updates.
Conclusion
For a strongly consistent, distributed metadata store such as Edgestore—serving 10 million requests per second and storing multiple petabytes of metadata—writes spanning multiple physical storage nodes are an inevitability. Although our initial “best-effort” approach to multi-shard writes worked well for most use cases, over time the balance of complexity shifted too heavily on developers. Therefore, we decided to tackle the problem of building a scalable primitive for multi-shard writes and implemented cross-shard transactions.
Although the basic protocol underlying our implementation has been known for a long time, actually retrofitting it into an existing system presented many challenges and required a creative approach to both implementation and validation. In the end, the up-front diligence paid dividends and enabled us to make a fundamental change to an existing system while maintaining our standards of trust and the safety of our users’ data. Think you’re up to the task? We’re hiring!
Thanks to: Tanay Lathia, Robert Escriva, Mihnea Giurgea, Bashar Al-Rawi, Bogdan Munteanu, Mehant Baid, Zviad Metreveli, Aaron Staley, and James Cowling.


