

Layer-7 load balancing (LB) is a core building block to scale today’s web services. In an earlier post, we introduced Bandaid, the service proxy we built in house at Dropbox that load balances the vast majority of our user requests to backend services. More balanced load distribution among backend servers is desirable because it improves the performance and reliability of our services which benefits our users. Our Traffic/Runtime team recently explored leveraging real-time load information from backend servers to make better load balancing decisions in Bandaid. In this post, we will share the experiences and results, as well as discussing load balancing in general.
It’s worth noting that the main idea we employed in this work has been presented in Netflix’s article Rethinking Netflix’s Edge Load Balancing. When we first read their post while working on this project, it was encouraging to see a similar approach being explored, and an interesting technical problem that attracts engineers in this field. By sharing our experiences and results obtained from the Dropbox production environment, we hope to contribute an additional data point showing the effectiveness of these approaches and highlight new challenges in load balancing.
Background: Request Load Balancing
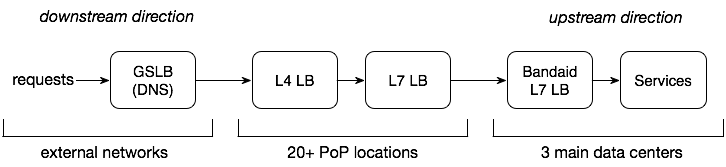
The figure above shows the load balancing stages a Dropbox user request goes through before it reaches backend services where application logics are executed. The Global Server Load Balancer (GSLB) distributes a user request to one of our 20+ Point of Presences (PoPs) via DNS. Within each PoP, TCP/IP (layer-4) load balancing determines which layer-7 load balancer (i.e., edge proxies) is used to early-terminate and forward this request to data centers. Inside a data center, Bandaid is a layer-7 load balancing gateway that routes this request to a suitable service.
In this post, we focus on layer-7 load balancing in Bandaid. Backend services (or application servers) are typically less performant compared with load balancers and contribute to the majority of request processing time. As a result, a better backend load distribution provided by Bandaid will improve the performance and reliability of our services.
New Challenges in Load Balancing
Load balancing in the networking area has been well studied and many load balancing methods exist. In this section, we first review the traditional load balancing methods and then discuss the challenges these methods face in a cloud environment where load balancing is performed distributedly. At the end, we present several high-level approaches to tackle these challenges.
Simple load balancing methods include random and round-robin, where LB instances determine the number of requests sent to each server solely based on the properties of the scheduling algorithms. These methods work well for basic use cases, however, the actual load distribution (load as in either CPU or thread utilization) is also affected by the processing time differences among requests. As an example, even with round-robin, where numbers of requests sent to each server are balanced, sending five low-cost requests to server A and sending five high-cost requests to server B will result in very different loads on these two servers. To address this issue, more advanced methods, such as least-connections, latency-based LB, and random N choices, are introduced where load balancers maintain local states of observed active request number, connection number, or request process latencies for each backend server so these load and performance information are taken into consideration in load balancing logics. Bandaid supports a rich set of load balancing methods, and we have shown the benefits of more advanced methods in the previous post.
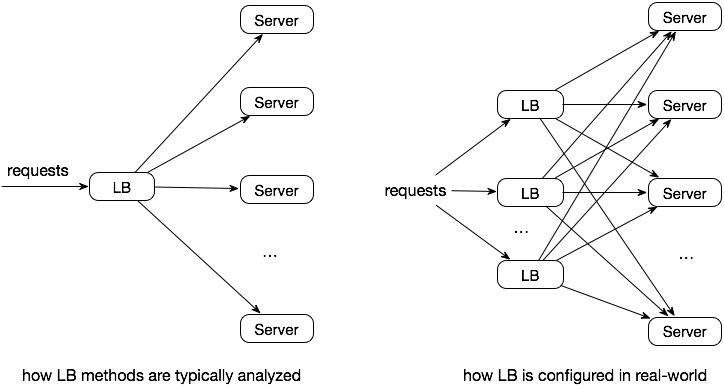
The existing load balancing methods are mostly analyzed with the assumption that only a single (likely hardware-based) load balancer is used to handle all the requests. However, in today’s cloud-based web service infrastructure, it is common to have tens or hundreds of software-based layer-7 load balancer instances routing requests distributedly to backend servers. As a result, there are new challenges for the traditional LB methods in real-world use cases.
- The local states stored in each LB instance track only the loads introduced from this specific instance and do not represent the real-time backend load. As a result, LB instances perform optimizations with local and often inaccurate information instead of global knowledge.
- Each LB instance may receive unequal amount of requests from downstream and therefore adds different amount of loads to backend servers.
- When the number of backend servers is large, LB instances may be configured with only subsets of the backend servers. Picking the right subset for each LB is challenging and basic methods such as randomly selecting subsets could result in skewed server distribution to load balancers.
- Processing time on a backend server varies for each request depending on the services and logics involved, making it challenging to predict server loads.
To tackle these challenges, a general direction is to leverage real-time metrics (such as server load information) to optimize load balancing decisions. Fortunately, a lot of performance and load information are readily available in the application layer, allowing us to follow this direction in practice. Several high-level approaches are listed as follows.
- Centralized controller. A centralized controller can dynamically schedule load distribution based on real-time request rates and backend server loads. This approach requires a data collection pipeline to gather information, advanced algorithms in the controller to optimize load distribution, and an infrastructure to distribute load balancing policies to LB instances.
- Shared states. States can be shared or exchanged across LB instances so that the information stored is closer to the real-time server status, however, keeping these states in sync at request rates can be challenging and complicated.
- Piggybacking server-side information in response messages. Instead of trying to aggregate stats based on local information, we could embed server-side information in response messages (e.g., stored in HTTP headers) to make it available on load balancers. Additionally, active probing (i.e., proactively sending a request from the load balancer to a server) can be introduced to force a refresh of the load information if necessary.
These approaches come with different pros and cons. In the next section, we discuss our Bandaid load balancing setup in production and how we took the third approach to enhance its load balancing performance.
Enhancing Bandaid Load Balancing
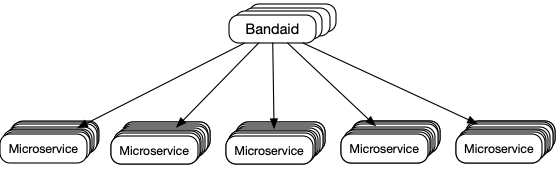
Although backend services share the same Bandaid deployment, resources can be logically isolated at service level (such as upstream workers, read more in the previous post). A specific load balancing method is configured for each service to work better with its workload characteristics. Previously, we used random N choices (where N=2 in most cases) based on numbers of active requests for most of our services. This LB method showed benefits compared with round-robin and least-connections, but loads among backend servers could still differ considerably, and some backend servers could be fully utilized at peak load. Although the impact of this behavior can be mitigated by increasing the number of servers or allow more aggressive retries from Bandaid (when the request is safe to retry), we started to look into better load balancing solutions.
Our Design
We considered the approaches discussed earlier and decided to start with the third one because it was simpler to implement and worked well with the random N choices LB method that Bandaid already supported. Additionally, there are a number of factors (such as our configurations or traffic patterns) that make our problem easier to solve.
- Bandaid
- Each Bandaid instance receives roughly the same number of requests (thanks to our downstream LB configurations), which reduces one factor of consideration.
- We have services that have Bandaid configured to send requests to all backend servers as well as ones where Bandaid is configured with randomly selected subsets of servers. Hence, we can easily validate the effectiveness of the solution in both scenarios.
- Backend servers (for each service)
- Each backend server is already configured with a maximum number of requests that can be concurrently served, and the number of active requests is also tracked in the server. As a result, it was straightforward to define the capacity and utilization of a backend server.
- The backend servers have homogeneous configurations, making it simpler to reason about load balancing among them. We believe the design should also work for heterogeneous configurations and will experiment with this as one of our future projects.
- Traffic patterns
- Because of the high QPS of our services, passively collecting piggybacked load information in response messages is sufficient to keep the stored information fresh and we do not have to implement active probing.
In our approach, each Bandaid instance still makes random N choice decisions, but instead of using the number of locally observed active requests as the metric when picking servers, now each server has a score to be used for this purpose. The scores are computed based on the following information.
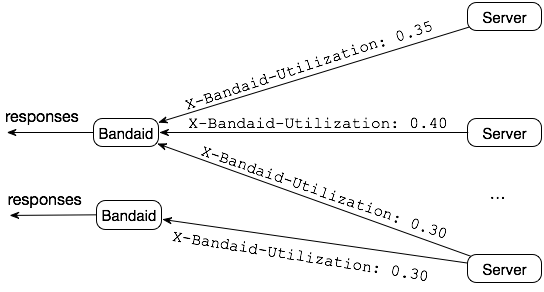
- Server utilization The server utilization is defined as the number of active requests over the maximum number of requests that can be concurrently processed at each server, ranging from 0.0 to 1.0. The utilization value is computed and stored in the
X-Bandaid-Utilizationheader when a response is about to be sent to Bandaid. The figure below shows an example of the response message flow.
- Handling HTTP errors
Server side errors (with HTTP status code 5xx) need to be taken into consideration, otherwise when a server fast fails requests, it may attract and fail more requests than expected due to the perceived lower load. In our case, we keep track of the timestamp of the latest observed error, and an additional weight is added to the score if the error happened recently.
- Stats decay
Because we haven’t implemented active probing, once Bandaid observes a high utilization value for a server, it will be less likely to send more requests to that server. Consequently, the stored server utilization value could get stuck and become stale. To address this, we introduced stats decay so the contribution of the stored utilization value decreases as time passes by. The decay function is defined as an inverted sigmoid curve, where T is a constant that represents the duration to reach sigmoid’s midpoint and
is the elapsed time since the stats have been recorded.
The score of a server is determined based on a function that computes the weighted sum of information listed above as well as a locally tracked active request number. In production, we rely more heavily on the server utilization value than other variables.
Performance Results
To rollout the new load balancing method, we first deployed changes in backend servers so that server utilization is correctly reported and added to HTTP responses. Then we deployed the Bandaid cluster and started to enable the new LB method service by service, starting from the least risky ones. We tuned the weights in the score function during the initial testing, then the same configuration was applied for the rest of the services. To evaluate the performance, we chose the distribution of total request processing time among backend servers as the metric because it represents the accumulated amount of time that a backend server is busy and serving some request. Note that this metric essentially reflects the number of active requests on servers, and we preferred the former because it is measured and reported more reliably than the number of active requests.
Results for a service without backend server subsetting
The figure below shows the distribution of total request processing time and total number of requests among backend servers for a service when we applied the new load balancing method. Each curve on the figure corresponds to the data series for a backend server. For this specific service, each Bandaid instance is configured with all backend servers, so subsetting is not involved.
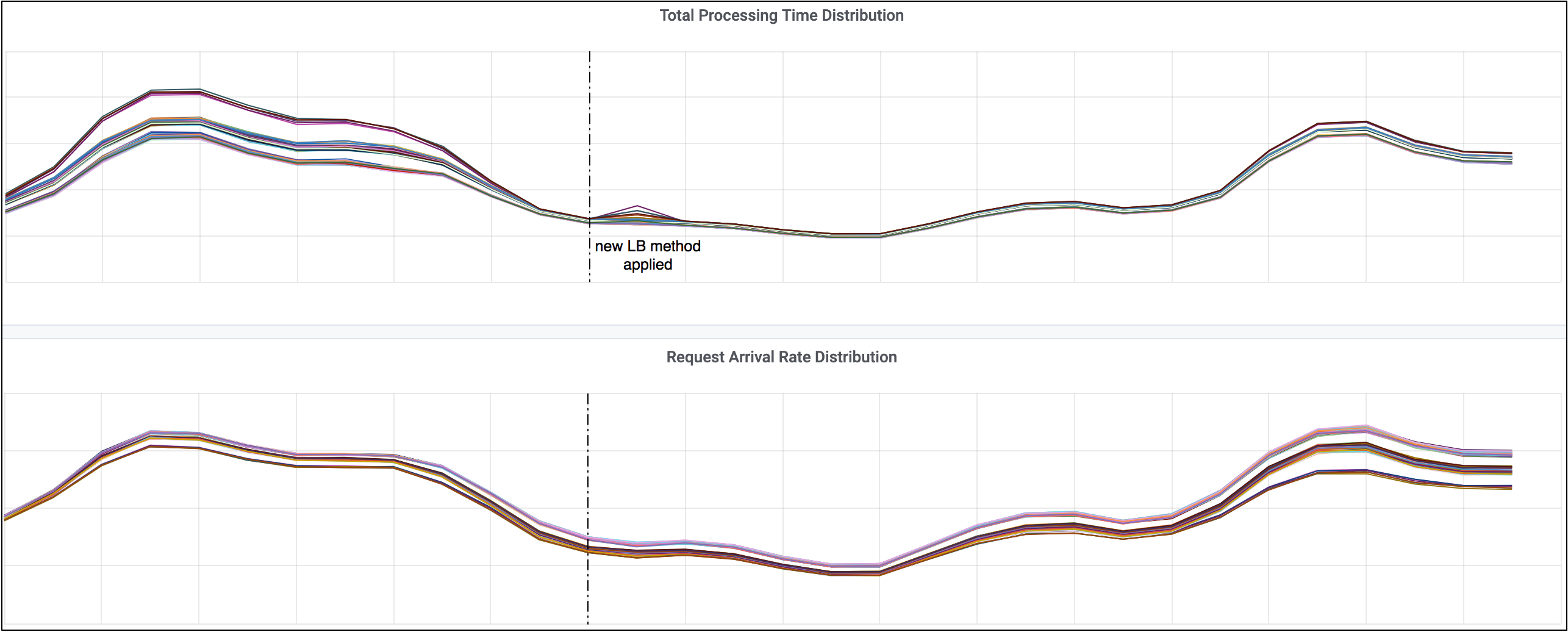
As can be seen, the total request processing time became more balanced (i.e., the spread became narrower) as we switched to the new LB method. In term of number of requests being processed at each server, the spread actually became wider in order to compensate the fact that requests took various amount of time to finish.
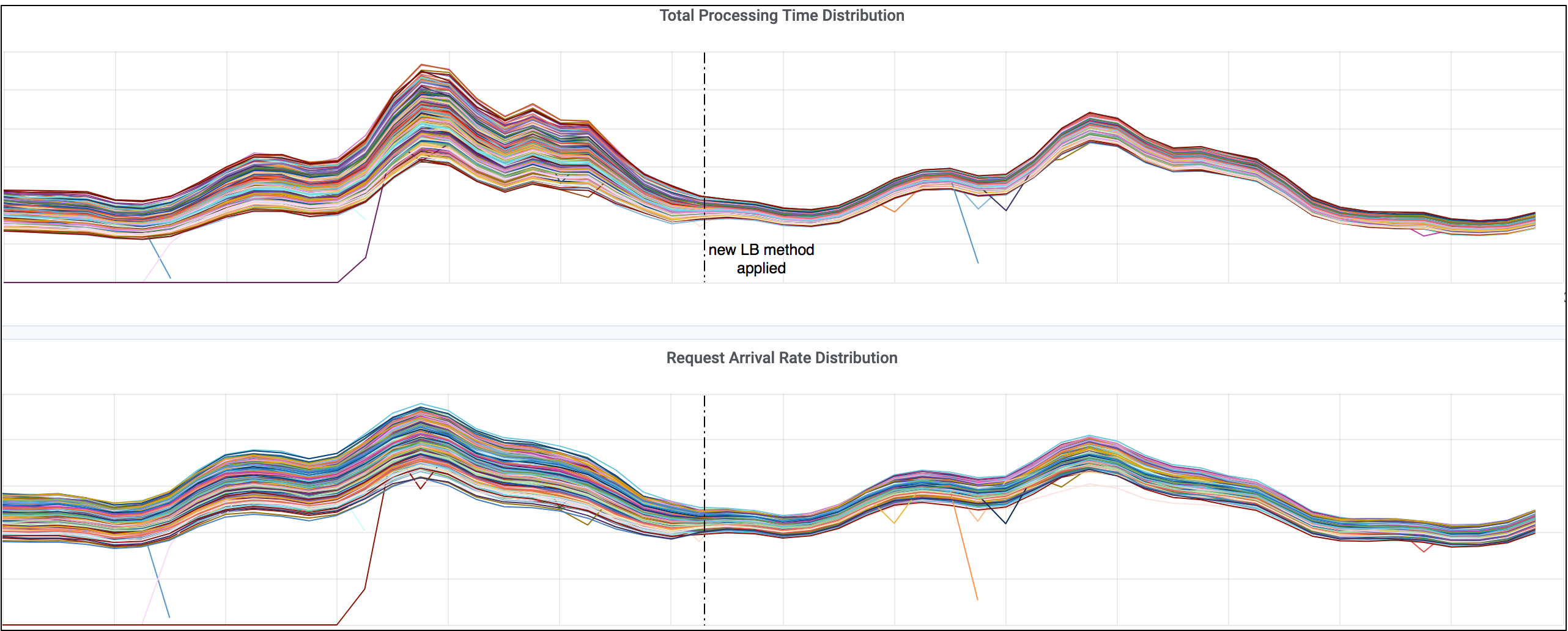
Results for a service with backend server subsetting
For a service where subsetting was enabled, we also observed improved load distribution with the new LB method. In our case, the subset of backend servers for each Bandaid instance were selected randomly, and even though the subset size was large, the overall server to balancer assignments were not balanced, indicated by the wide spread of request arrival rates at the servers. As shown on the figure below, switching to the new LB method also made request arrival rates more balanced. Exploring alternative solutions to better improve subsetting is something we plan to work on in the future.
Discussion
In this section, we discuss load balancing for service-oriented architecture (SOA) and how to leverage real-time metrics to optimize system performance.
Load balancing in service-oriented architecture
At Dropbox, we are in the process of moving from a monolith towards a service-oriented architecture. Our internal services do not rely on a dedicated load balancing layer (i.e., server-side load balancing) when they communicate with each other but rather each client directly load balances requests across a subset of upstream servers (i.e., client-side load balancing). To some extent, Bandaid load balancing (i.e., a server-side load balancing cluster) is a special case of client-side load balancing, and the approach we took for improving Bandaid load balancing could potentially be applied to our SOA framework. As for related work, Google presents their load balancing approaches comprehensively in the Load Balancing in the Datacenter chapter of the Google SRE book. For those who are interested in the issues with subsetting, this chapter also discusses deterministic subsetting, a desirable feature for load balancing use cases.
Leverage real-time metrics to optimize system performance
The core concept of our work is to leverage real-time information to make better load balancing decisions. We chose to piggyback the server load information in HTTP responses because it was simple to implement and worked well with our setup. Netflix presents a similar approach to optimize load balancing for their edge gateway. Google also discusses a solution to send server-side information to clients in response messages, but weighted round robin is used as the client-side load balancing method instead of random N choices. With the rich set of metrics reported at the application layer, it will also be possible to gather and process all related real-time information in a centralized controller or orchestrator to make more sophisticated optimizations. Although we focus on layer-7 load balancing in this post, the same concept can be applied to various system performance optimization problems.
Conclusion and Future Work
Traditional load balancing methods face new challenges in real-world use cases where load balancing is performed distributedly via many load balancer instances. In this post, we discuss these challenges and general approaches to address them. We also present our solution to enhance load balancing in Bandaid, the Dropbox service proxy. We demonstrate the effectiveness of the implementation by sharing the improved backend server load distribution obtained from Dropbox production workload.
The load balancing method presented in this post has been running in our production environment for several months. In the next steps, we are looking into testing the new LB method with heterogeneous backend server configurations and improving load balancing in our SOA framework.
If you are interested in high-performance packet processing, intelligent load balancing, grpc-based service mesh, or solving new challenges in scalable networked systems in general, we’re hiring!


