

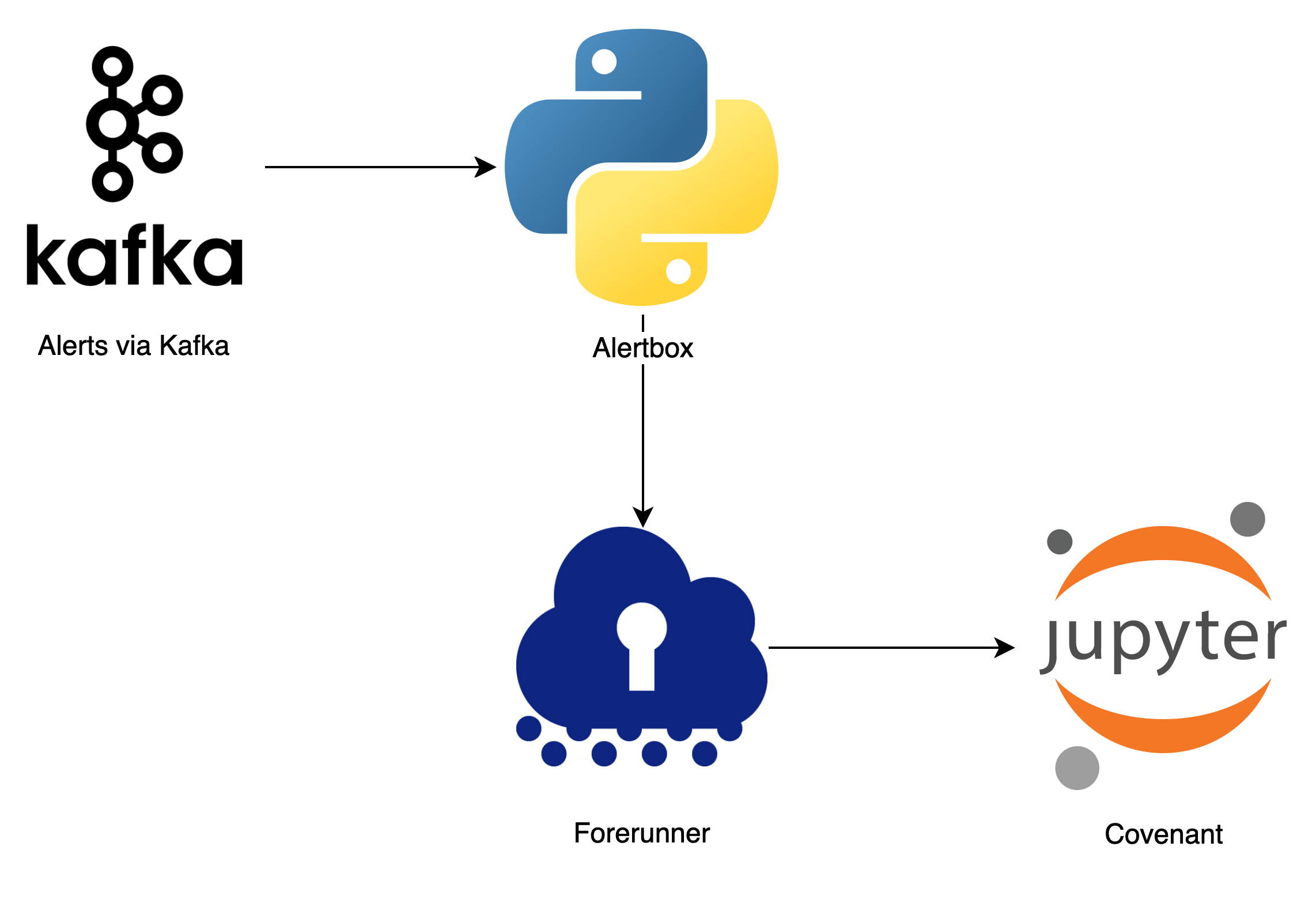
The problem we’re solving
Apart from building detections to track suspicious behavior and triaging incidents, we also spend large chunks of our time triaging false positive alerts and building context around individual alerts. This was time not spent hunting for attackers. As a result, any way to automate or improve triage process efficiency was appealing.
Our massive log volume also imposed some constraints. One such constraint is that we can’t keep all of our logs in one place. Currently, the volume and source of logs determines which data store they go into. Another factor which comes into play is the type of queries we want to write against that log type. Unfortunately, this imposed a burden on data analysis. For example, during investigations, we would have to search through logs stored across multiple data stores to understand the full picture.
The use of different data stores also forced the team to learn multiple query languages with different properties and interfaces. This made on-boarding new team members more difficult. This fragmentation of data also meant that we could not easily contextualize our rules. If a rule triggers on some events, it was cumbersome to then pull context across other data stores.
To simplify things, our team wanted a common language and interface to query logs stored in different data stores. Also, we wanted the same set of core tools for various stages of the Incident Response cycle — building detections, contextualizing alerts, threat hunting and actual response.
Building Alertbox to contextualize alerts
Alertbox was the first project we built to start cutting down on our triage time. The goal was to move our alert response runbooks into code, and have them execute before we even begin the triage process.
The first steps in our alert runbooks were often about gaining initial context—information about users, hosts, and processes involved in the alert. To receive this necessary context, DART would often have to query a database or custom internal service. We couldn’t easily implement those queries in our SIEM (Security Information and Event Management), where the majority of alerts fired from, since the data we wanted lived elsewhere.
What we needed was a way to run code in response to these alerts, which would allow us to interface with our various datasources and build in custom logic or context.
We built Alertbox around the concept of a Workflow, which is a Python class that maps to a particular alert. Python was the obvious choice for Alertbox, as Dropbox is heavily invested in the language and it’s the most popular language in the security and data science communities.
In the snippet below, the “Default Workflow” acts as a catch-all for any alerts that did not have their own workflow.
class DefaultSIEMEventWorkflow(Workflow[SIEMEvent]):
def __init__(self, siem_client, jira, forerunner):
# type: (SIEMClient, JiraAPI, ForeRunnerAPI) -> None
self.jira = jira
self.siem_client = siem_client
self.forerunner = forerunner
@classmethod
def create_instance(cls):
# type: () -> DefaultSIEMEventWorkflow
jira = JiraAPI('dart-bot')
siem_client = create_siem_client()
forerunner = ForeRunnerAPI()
return DefaultSIEMEventWorkflow(siem_client, jira, forerunner)
def process_event(self, workflow_context):
# type: (WorkflowContext[SIEMEvent]) -> None
alert_name = workflow_context.event.name
event = workflow_context.event
url = event.url
runbook = extract_runbook_url(event.logs[0])
jupyter_notebook_url = self.forerunner.generate_jupyter_notebook_url(
alert_name=alert_name, alert_content=event.logs[0]
)
tags = extract_tags(event.logs)
table = Table.convert_to_table('Raw Logs', event.logs)
try_create_jira_ticket(self.jira, alert_name, url, jupyter_notebook_url, tags, runbook, table)Abstracting datasources and encapsulating logic
Alertbox gave us the orchestration and workflow abstraction that allowed us to write custom code in response to alerts. The next step was to start building out libraries for the workflows to leverage, allowing us to pull in context more easily, write workflows more quickly, and avoid thinking about implementation details such as where our data lived.
We built out a ‘datasources’ library for this purpose—a Python library with groups of modules that could abstract away the details we didn’t care about.
class AuditExecLog(Log):
def __init__(
self,
auid, # type: int
node, # type: str
uid, # type: int
pid, # type: int
ppid, # type: int
comm, # type: str
euid, # type: str
proctitle, # type: str
timestamp, # type: int
username, # type: str
):
pass
def get_children(self):
# type: () -> List[AuditExecLog]
"""
Find execution of processes where the parent process is `self`
:return: List of AuditExecLog, representing child processes
"""@cached
def get_machine_profile(client, hostname):
# type: (MPClient, str) -> Optional[MachineProfileEntry]
query = build_mp_query(hostname)
response = MachineProfileEntry.query(client, query)
return response or None
We began creating very low level abstractions that map directly to our underlying data stores. One example of this is the AuditExecLog, which is a Python wrapper for the Linux audit subsystem’s log format.
Given a suspicious execution log, we would often want to pull in related executions, such as child processes. Pulling in related executions is actually somewhat complex when working with raw queries such as handling issues like PID collisions. Our datasources library encapsulates all of that complexity into a simple method call, get_children, making an otherwise complex query trivial.
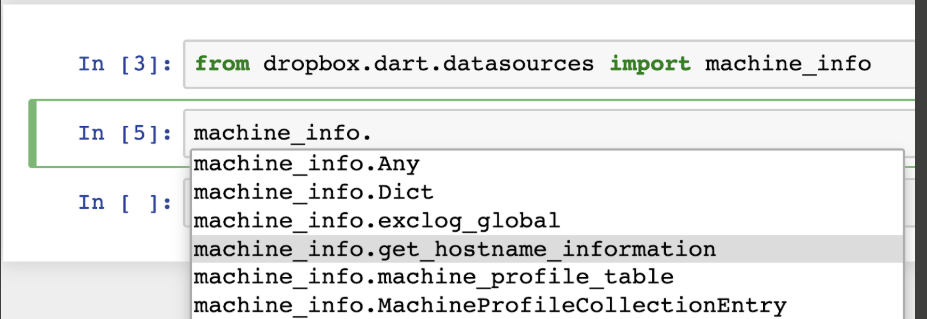
We also need to understand the systems involved in our investigations. DART tracks and stores information on every asset in Dropbox’s various environments such as the status of tooling on the system, any associated owners or teams, ip addresses, hostnames, etc. This aggregate information is stored in an entity called Machine Profile.
Below is a simple helper function to look up a MachineProfileEntry by just passing in a hostname. This helper encapsulates logic for caching results, building out the raw query, and parsing out the result into a Python object: MachineProfileEntry.
@cached
def get_machine_profile(client, hostname):
# type: (MPClient, str) -> Optional[MachineProfileEntry]
query = build_mp_query(hostname)
response = MachineProfileEntry.query(client, query)
return response or None
Performing investigations and threat hunting in Covenant
Alertbox and the datasources library allowed us to build automated responses to our alerts, but investigations still required knowing where the data actually lived, the underlying data abstractions, and the multiple query languages. This disconnect between the primitives available for automation and what was required for actual investigations was cumbersome. In order to tackle this, we built Covenant, our investigation tool built on top of Jupyter Notebooks.
If you’re unfamiliar with Jupyter Notebooks, think of them as a super powered Python REPL. The building blocks of Jupyter notebooks are cells, which can be populated with Python code or Markdown. You can then modify the Python code that’s written in the cell and re-execute the cells as you choose. Jupyter Notebooks are a very powerful and popular tool with the data science community where they’re used for slicing data, building up models, and sharing reports—work that’s very closely aligned with what we do on DART.
One of the key design decisions behind Covenant was that the fundamental abstractions and tools for working with the data should be common between the automation and the investigation platforms.
Covenant achieves this by using Bazel, an open source build system similar to Make), which works with various programming languages (like Python) and allows us to specify dependencies.
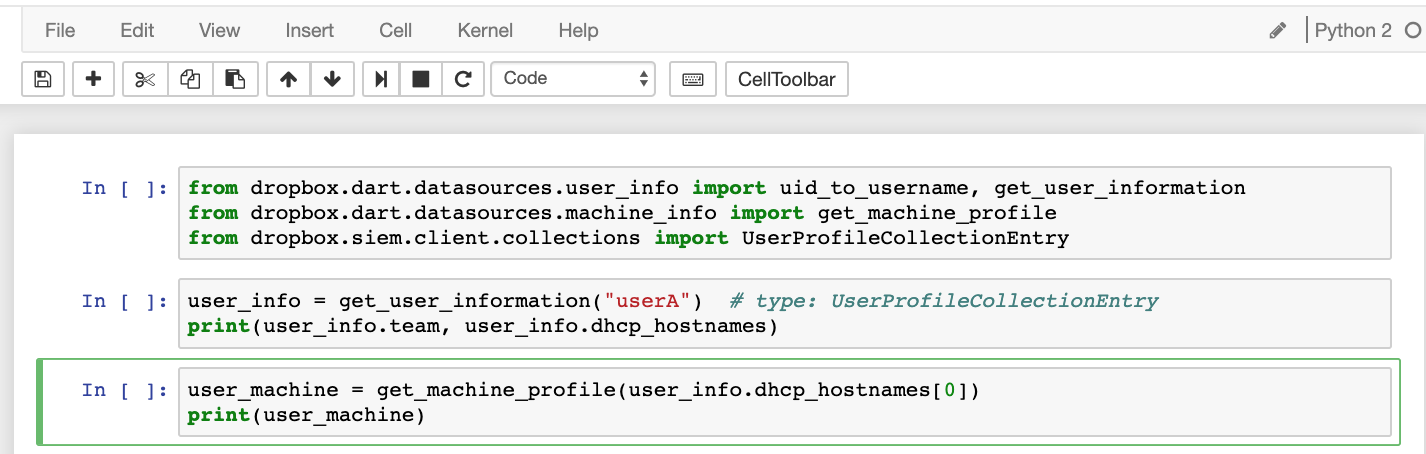
Instead of using a vanilla Jupyter environment, Covenant uses a custom Bazel-built kernel with a dependency on the datasources library. This allows us to start interacting with our data and conduct hunting exercises, using the existing primitives used to contextualize/respond to alerts.
How do we secure Covenant?
Covenant is an incredibly powerful tool: it is effectively a remote Python shell. And Jupyter itself is not immune to vulnerabilities. So we took a lot of steps to secure it:
- Covenant doesn’t have direct access to the internet and no packages are pulled directly from the internet during the build process
- Covenant sits behind a proxy where we enforce strong 2FA based authentication and authorization checks to ensure only members of DART have access. For defense in depth, Covenant also uses application level authentication
- We implement a strong Content Security Policy, and enforce CSRF protection for both
GETandPOSTrequests using SameSite cookies (Check out The Call is Coming From Inside the House: Lessons in Securing Internal Apps talk given by our own Hongyi Hu)
Putting Everything Together with Forerunner
Code and output are intermingled and any analysis is self-documented in Jupyter notebooks. We wanted to leverage this to record any analysis/investigations performed and tie them to individual alerts fired.
Think of Forerunner as the glue between Alertbox and Covenant. When an alert fires, Alertbox calls out a RPC service called Forerunner. This service returns a Jupyter notebook corresponding to the alert. Alertbox then embeds the URL of this Jupyter notebook into the alert ticket. In the background, Forerunner also runs this alert notebook asynchronously.
The notebooks usually contains heavier queries that pull even more context for that alert. The on-call may then conduct their investigation in the notebook using the same primitives developed in the datasources library. These investigations are automatically recorded.

Conclusion
Traditionally, the most common method of building threat detection and response tools is to de-couple the automation and investigation pieces. In our experience, this leads to a massive amount of thrash. At Dropbox, we have invested in a common underlying abstraction for our logs which is available during various stages of the Incident Response cycle via Alertbox, Covenant, and Forerunner. Integrating and leveraging powerful open source tools has enabled us to quickly explore our data and automate alerts away so we can focus on more sophisticated threats.
If you have a passion for security and exploring threats at scale, our team is hiring.


