

At Dropbox, we are building smart features that use machine intelligence to help reduce people’s busywork. Since introducing content suggestions, which we described in our previous blog post, we have been improving the underlying infrastructure and machine learning algorithms that power content suggestions.
One new challenge we faced during this iteration of content suggestions was the disparate types of content we wanted to support. In Dropbox, we have various kinds of content—files, folders, Google Docs, Microsoft Office documents, and our own Dropbox Paper. Regardless of the types of content our users work with, we want to make sure that the most relevant content is available for them at their fingertips. However, these types of content live in different persistent stores, have different metadata, and are used to varying extents by different users. This made it difficult to create a single machine learning pipeline to rule them all, so to speak.
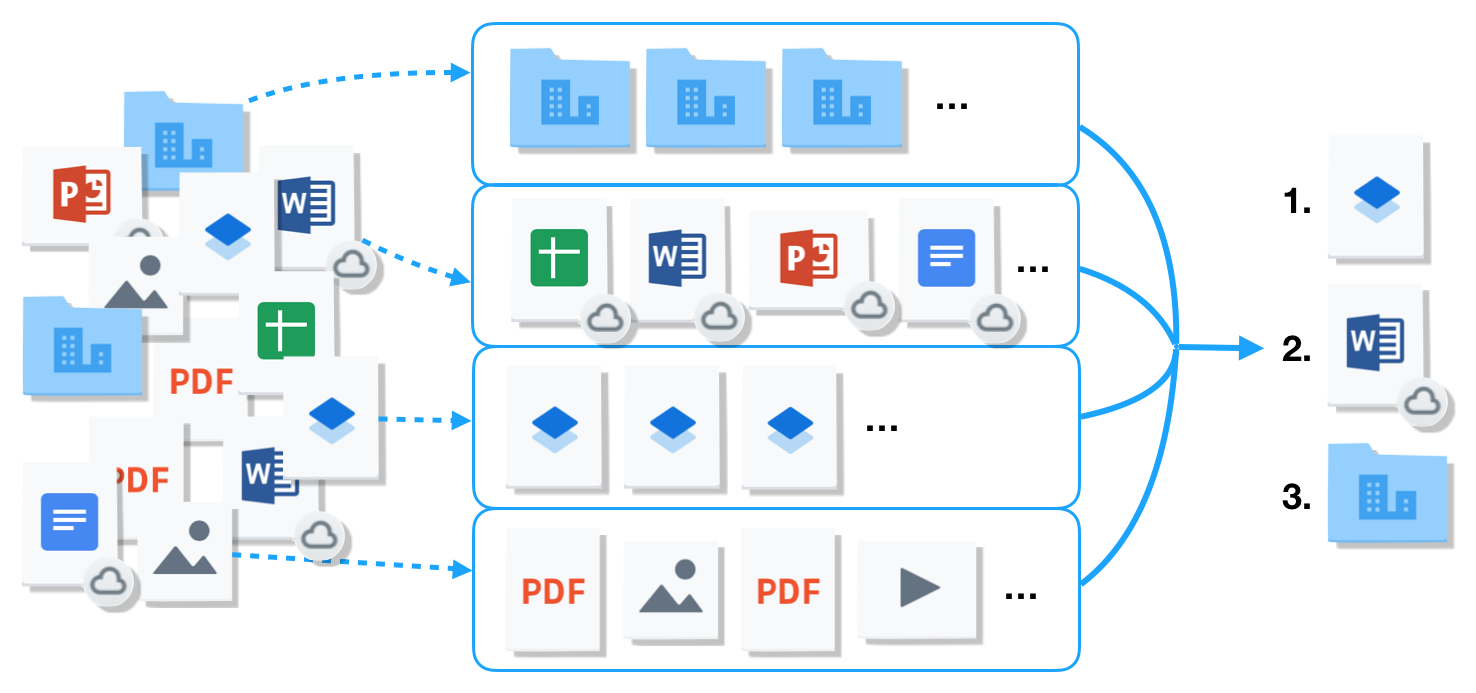
While waiting for the underlying infrastructure to catch up, we decided to tackle these types individually, in order to bring improved suggestions to our users more quickly. In the rest of this blog post, we will describe how we trained and improved ML models for these types of content, and how we were able to combine them in a principled way. We will also describe the improved tooling we built and used along the way.
Improving file suggestions
Once we released content suggestions on the Dropbox homepage in April, we immediately set out to improve the performance of the ML model. We approached this task from two different angles: first, how do we incorporate more signals to make better predictions? Next, how can we train a model to better use these signals?
In the previous blog post, we mentioned that we wanted to incorporate the type of a file when making predictions. There are many ways to define and categorize the type of a file, however; for instance, one could have a sparse set of major categories (e.g. texts, images, videos), a more fine-grained set of categories (e.g. raw texts, web documents, source codes, word-processor files), or even semantic categories (e.g. contracts, receipts, screenshots, proposals). In our case, we began with file extensions, as this information is generally available at both training and inference time and can embody some of the essential properties of a file.
One could naively encode the file extensions as one-hot vectors, where the dimensionality of the vectors is the number of all possible file extensions. However, this is not ideal for two reasons: first, the vectors can be very high-dimensional and sparse, which requires models capable of extracting useful signals from these vectors. Second (and more importantly), the distribution of the file extensions is very heavy-tailed, meaning that it is difficult for the model to learn about the more exotic extensions.
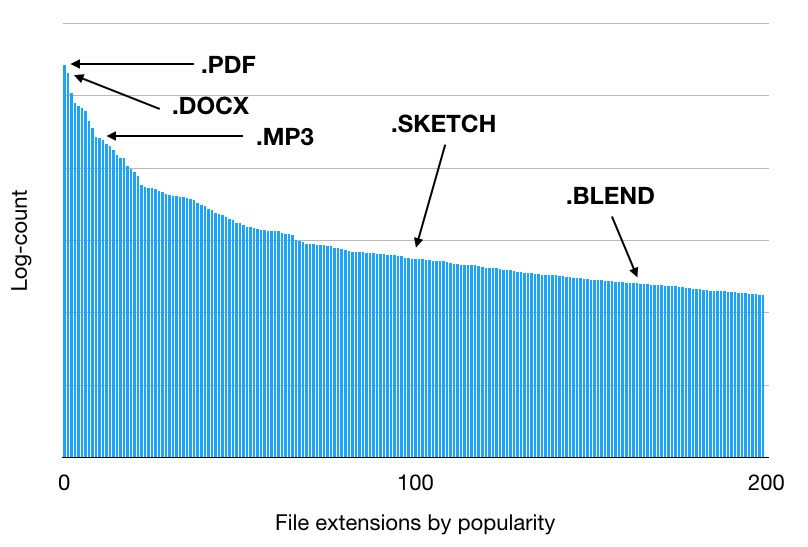
To combat these problems, we decided to create a file extension embedding trained from a weakly-supervised task—we will describe this in our next blog post, but in a nutshell, we trained the file extension embedding to predict the likelihood of two file extensions co-occurring in a single upload in Dropbox. This yielded a dense vector with low dimensionality, such that semantically similar file extensions (e.g. JPEGs and PNGs) were close in the embedding space. This enabled our model to effectively learn from unevenly distributed data, improving both the offline and online performance of our model.
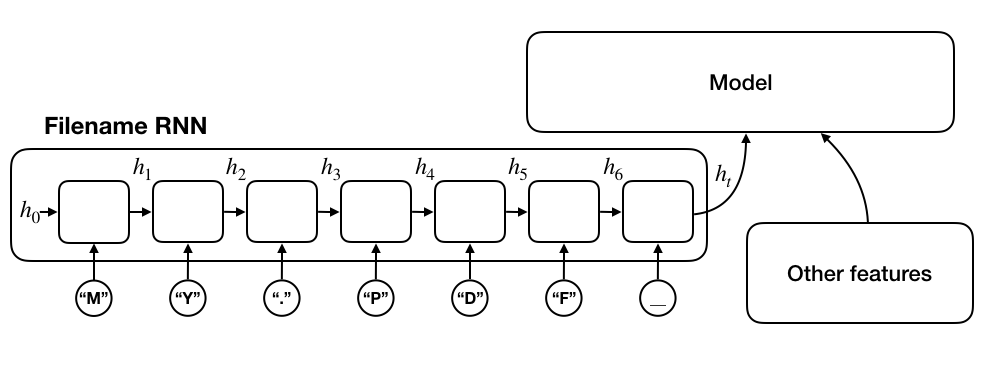
Another important piece of signal we elected to use is filenames. For instance, when the model encounters a PDF file, it may know that it is a textual document, but will not have any idea what kind of document it is. If the filenames are available, the model may find some clue in it. In our first attempt to incorporate filenames as a signal, we treated a filename as a bag of characters, akin to the bag-of-words model in NLP. While this model failed to capture the semantic meaning of a given filename, we did see some improvement in our offline evaluation as this feature could help the model identify whether the file was a user-generated file or a programmatically generated one. We later moved to a sequential model with a char-RNN, which ingested one character of the filename at a time. The state vector of the char-RNN after all the characters were ingested would serve as the embedding vector for the filename. Such a sequential model is better at detecting temporary filenames, e.g. j8i2ex915ed.bin.
Handling cloud-based documents
As mentioned in the introduction, Dropbox supports various third-party content. It is possible to create cloud-based files (such as Google Docs and Microsoft Office 365 files) all within Dropbox. We aimed to support such content types in the content suggestions model, but realized that for these relatively recent partnerships, the amount of training data available was much smaller than for your everyday files—like PDFs and JPEGs. As such, we ended up crafting a separate dataset, and instead of merging this dataset with the main file suggestions dataset, we trained a separate model using the same network architecture.
Building folder suggestions
The most important goal of content suggestions is to enable our users to find their important files quickly. However, from a quick-and-dirty online experiment, we observed that the click-through rate was measurably higher for folders—we did this by mixing in some folders, generated from a heuristic, with the files suggested by the original (file-only) content suggestions model. We hypothesized that the user may want to have a quick access to the folder that contains their working files, even if it meant an extra click to get to the files. Conveniently, suggesting a folder is a reasonable alternative to suggesting multiple files therein—while the folder itself might not be precise, this can improve the overall recall (by saving rooms for other suggestions) if we are willing to tolerate the potential extra click to get to the file.
Now, whether it was better to suggest an important file or its parent folder is an interesting question, but it was one that could only be answered by feedbacks from our users. Hence, we made a tactical decision early on to decouple file suggestions and folder suggestions from each other. This did not prevent us from reusing the offline data and training pipeline—which we had built for powering file suggestions—for folder suggestions. We trained separate models and then later used a combiner model to mix the two resulting lists of candidates, discussed in a later section of this post.
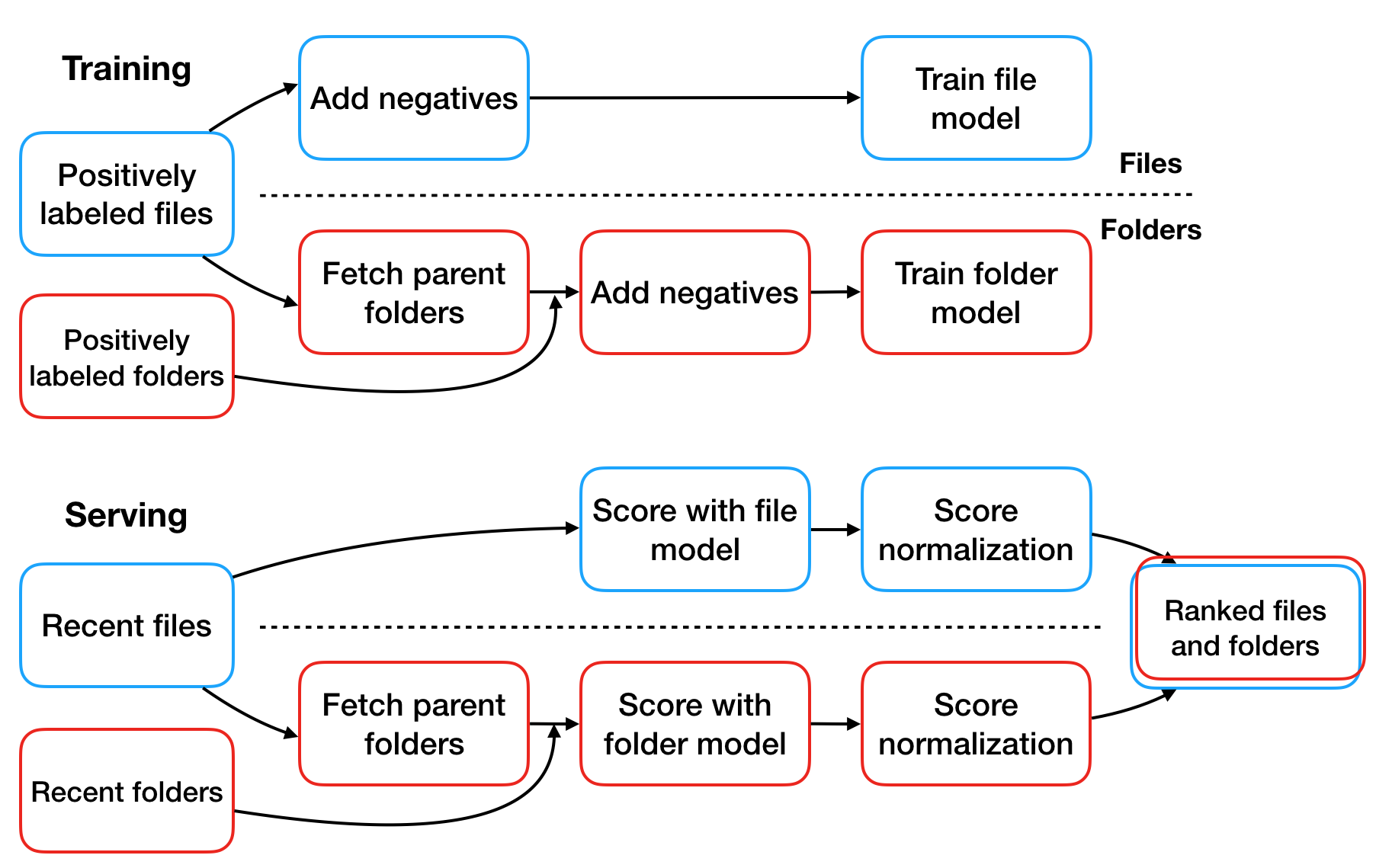
While reusing the existing pipeline, we made the following tweaks appropriate for handling folders.
- Generating candidates: for file suggestions, it sufficed to obtain the list of files for which the user had registered an event most recently; however, for folder suggestions, we took the parent folders of such files, in addition to any folders that had a registered event.
- Fetching signals: for file suggestions, we fetched the events on the candidate files for the last 90 days, but for folder suggestions, we fetched the events for the files belonging to the candidate folders, in addition to the events on the candidate folders themselves. This allowed the model to recognize folders that might have had numerous “low-importance” files, as well as folders that have few “high-importance” files, and let it adjudicate which should be ranked higher.
- Creating training data: in our previous blog post, we mentioned that we used two sources to obtain positive candidates for the offline dataset: first, we had labeled data from running online experiments with heuristics; second, we had an unsupervised dataset of user events in Dropbox, from which we could create a supervised dataset for predicting whether a file would be interacted with in the near future. For the second case, the definition of this future interaction was changed to encompass both a direct operation on the folder and an operation on some files in the folder.
With these changes in place for the offline pipeline, we could train a model to score folders in the same way we scored files.
Aside: improving training infrastructure
Although the neural network we had been using was not very deep, we had many new signals, datasets, and tweaks that we were experimenting with, as described in the previous sections. This made rerunning experiments and tuning hyperparameters a repetitive chore, especially since the hyperparameter set was fairly large—the depth and width of the network, the choice of optimizer, learning rate, activation function and regularizer, to name a few. Previously, we had used a naive grid search for optimizing these hyperparameters. However, it is well known that the grid search method can be costly and ineffective.
To better conduct the training jobs, our machine learning infrastructure team built a tool called dbxlearn. dbxlearn is an elastic and scalable computing environment for machine-learning training and provides more advanced algorithms, such as Bayesian Optimization, for hyperparameter tuning. With dbxlearn, we have been able to perform many more tuning jobs for offline experiments—and test different signals, data, and models in much faster iteration—to deliver the best model and user experience with content suggestions.
Handling Paper docs
As of last week, Paper docs are now part of the Dropbox filesystem. However, as the development of our content suggestions models preceded this migration, we needed to temporarily support Paper docs that were (previously) not a part of a user’s Dropbox. As we did with cloud-based documents, we decided to create a separate dataset and heuristic for handling Paper docs, and merge the results intelligently, as we discuss in the next section.
Bringing the models together
As hinted earlier, we developed individual models for each of the content types. The key challenge that arises then is to rank the suggestions generated by each of these submodels against one another. To achieve this, we modeled the scores generated by each of the submodels as a blackbox function with the following properties:
- For each submodel, there exists a function
that maps the score generated by the submodel to the expected CTR for a suggested item of the given score.
If such
In practice, we further assumed that 


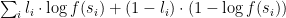
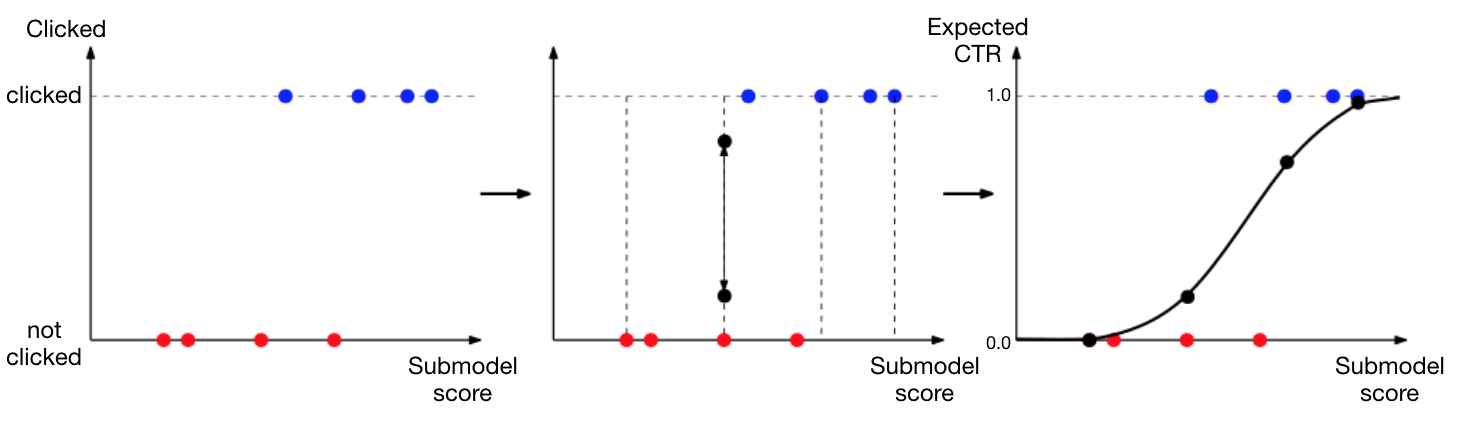
Solving for these normalizing functions requires an initial online experiment that can measure how likely it is that an item of a particular score is clicked. To bootstrap this problem, we first ran the submodels as shadows to the production models—meaning that we generated candidates and scores without showing them to users. We then aligned the resulting histograms of scores, yielding a simple affine transform of the scores, which we used to create the initial mixture model. This mixture model was then used in a new online experiment shown to the users, generating the scores and labels needed in the illustration above. We were then able to verify that a new mixture model generated with the normalizing functions yielded better CTR overall.
Conclusion
We evaluated each of the improvements and layering techniques discussed in the earlier sections via online A/B tests on our users’ logged-in home pages until we reached statistical significance, in addition to other experimental ideas. Some of the experiments we ran yielded negative results and did not get incorporated into the production model. All in all, we were able to increase the percentage of user sessions with at least one clicked suggestions by more than 50%, which gave us the confidence to roll out the production model at scale.
Launching a machine-intelligence-powered feature to all users of Dropbox is an endeavor made possible by the collaboration among many teams. In addition to the work of machine learning engineers, the work of ML infrastructure teams and of teams building the user experience around the intelligent suggestions was equally critical to delivering value to our users. If you are interested in working on intelligent products, machine learning systems, and infrastructure, come join us. We’re hiring!


