

Many moons ago, I was working at the New York Times and created a library called Store, which was “a Java library for effortless, reactive data loading.” We built Store using RxJava and patterns adopted from Guava’s Cache implementatio n. Today’s app users expect data updates to flow in and out of the UI without having to do things like pulling to refresh or navigating back and forth between screens. Reactive front ends led me to think of how we can have declarative data stores with simple APIs that abstract complex features like multi-request throttling and disk caching that are needed in modern mobile applications. Fast forward three years, Store has 45 contributors and more than 3,500 stars on Github. Today, I am delighted to announce Dropbox will be taking over active development of Store and releasing it in 100% Kotlin backed by Coroutines and Flow. Store 4 is an opportunity to take what we learned while rethinking the api and current needs of the Android ecosystem.
Android has come a long way in the last few years. The pattern of putting networking code in Activities and Fragments is a thing of the past. Instead, the community is increasingly converging on new, useful libraries from Google. These libraries, combined with architecture documentation and suggestions, now form the foundation of modern Android development. As an example, here’s Android Jetpack’s guide to Android architecture:
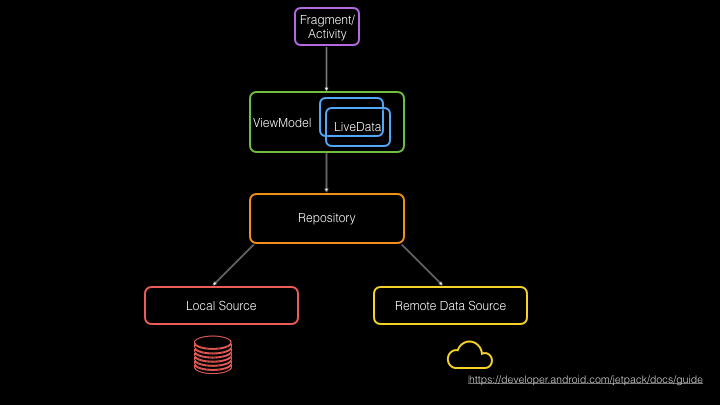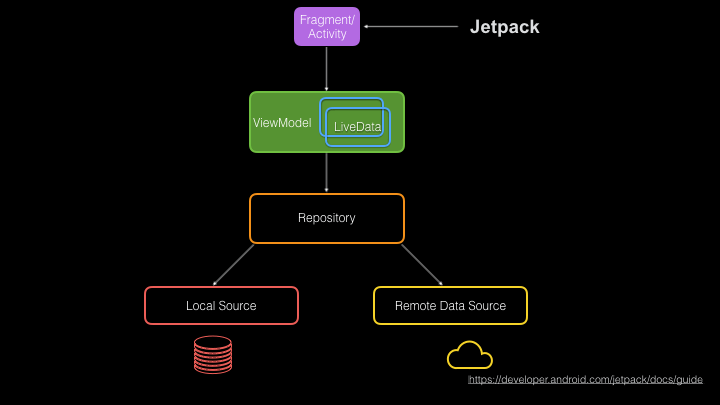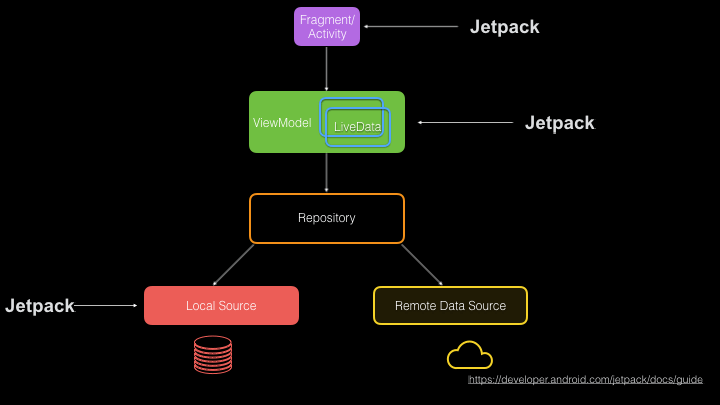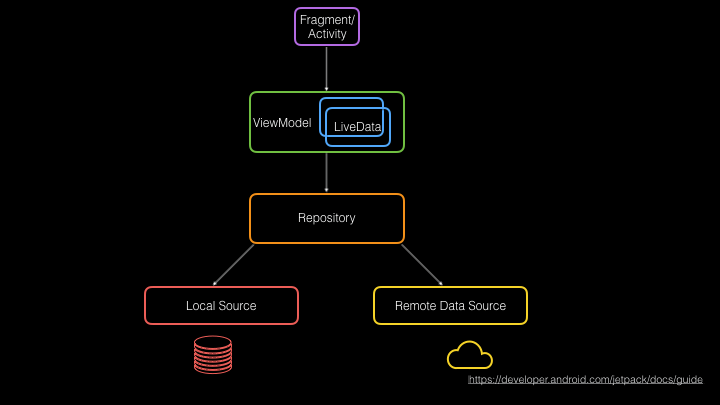
- Fragments and Activities: These have always been around, but now have AndroidX versions with things like Lifecycle and Scopes for coroutines. Fragments and Activities give us what we need to build the view layer of our app.
- View Model and Live Data: These help us transmit data that we get from repositories without needing to manage rotation and lifecycle ourselves (Wow, we’ve come a long way!)
- Room: Takes the complexities out of working with SQLite by providing us a full-fledged ORM with RxJava and coroutines support.
- Remote Data Source: While not a part of Jetpack, Square’s Retrofit and Okhttp have solved network access in two different levels of abstraction.
Careful readers may have noticed that I skipped over Repository (not just me, it seems like Jetpack team also skipped it 😉 ). Repository currently only has a few code samples and no reusable abstractions that work across different implementations. That’s one of the big reasons why Dropbox is investing in Store—to solve this gap in the architecture model above. Before diving into Store’s implementation, let’s review the definition of a repository. Microsoft offers a nice definition, describing repositories as:
“classes or components that encapsulate the logic required to access data sources . They centralize common data access functionality, providing better maintainability and decoupling the infrastructure or technology used to access databases from the domain model layer.”
Repositories allow us to work with data in a declarative way. When you declare a repository, you define how to fetch data, how to cache it, and what you will use to transmit it. Clients can then declare request objects for the pieces of data they care about, and the repository handles the rest.
What problem is Store trying to solve?
Four years ago, when we before we began working on Store, preventing complex Android apps from using large amounts of data was a struggle. It was a significant engineering challenge to figure out how to keep network usage low while maintaining always-on connectivity. Most companies opted for always-on connectivity to ensure the best user experience.
Unfortunately, most users’ cell phone bills scale with the amount of data used, so this approach was more expensive for users. With that in mind, it was important for apps to find ways to keep data usage to a minimum. We created Store in part, to address this problem and make it easy for engineers to keep data usage low.
A major contributor to this problem of large data usage was duplicate requests for the same data. A common example…

Store solved the problem:
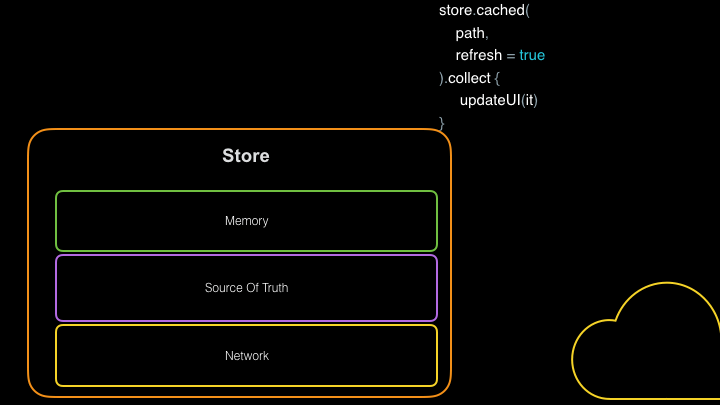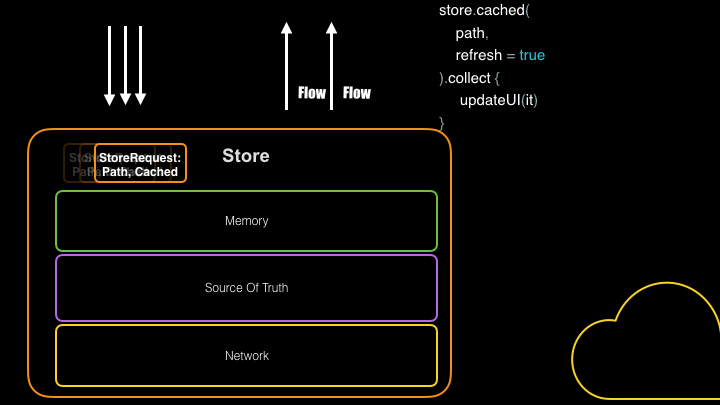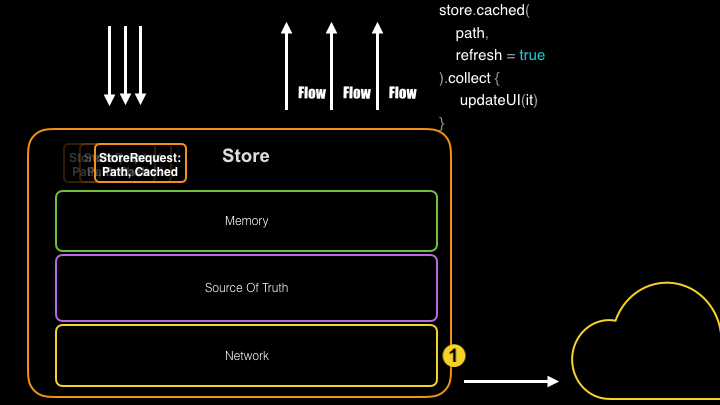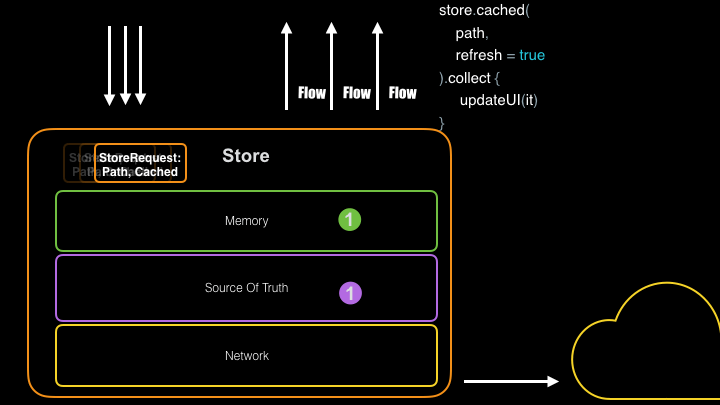
As you can see above, having a repository abstraction like Store gives you a centralized place to manage your requests and responses, allowing you to multicast both loading, error, and data responses rather than doing the same work many times.
Fast forward 4 years and the world of Android has changed at breakneck speed. Previously, we were working with network and databases that returned scalar values. Now, with the release of Room and SQLDelight, applications can subscribe for changes to data that they require. Similarly, websockets, push libraries like Firebase, and other “live” network sources are becoming more prevalent. Originally, Store was not written to handle these new observable data sources, but given their new prevalence we decided it was time for a rewrite. After much collaboration and many late nights, we’re pleased to introduce the fourth version of Store: github.com/dropbox/Store.
Store 4 is completely written in Kotlin. We also replaced RxJava with Kotlin’s newly-stable, reactive streams implementation called Flow.
You might be asking, Why ditch an industry leader like RxJava? First and most importantly is the concept of structured concurrency. Structured concurrency means defining the scope or context where background operations will run before making a request rather than after. This matters because the way scoping of background work is handled has a huge impact on avoiding memory leaks. Requiring scope to be defined at the beginning of the background work ensures that when that work is complete or no longer needed, the resources are guaranteed to be cleaned up.
Structured concurrency is not the only way to define the scope of background work. RxJava solves the same problem in a different way. Let’s look at RxJava’s core API for defining the scope of background work:
// Observable.java
@CheckReturnValue
public final Disposable subscribe(Consumer onNext) {} Notice in the method signature above, RxJava Observable will return a disposable as the handle of the subscription. The disposable has a function dispose which tells the upstream observable to detach the consumer from itself. The scope background operation is defined between the start of the subscription and the call to this dispose method. Recently, RxJava2 added @CheckReturnValue, an annotation to denote that a call to flowable.subscribe will return a value and a user should retain it to use for future cancellation. Unfortunately, this is only a lint warning and will not prevent compilation. Think of it as RxJava warning you not to leak.
The big problem with RxJava’s approach to scoping background operations is that it’s too easy for engineers to forget to call dispose . Failing to dispose of active subscriptions directly leads to memory leaks. Unlike RxJava, which lets you first start an observable and then reminds you to handle the cancellation or detachment later, Kotlin Flow forces you to define when observables should be disposed right when you create the data source. This is because Flow is implemented to respect structured concurrency. Let’s take a look at Flow and how it prevents leaks.
suspend fun Flow.collect(...)Collect is similar to subscribe in RxJava, it takes a consumer that gets called with each emissions from the flow. Unlike RxJava, Flow's collect function is marked with suspend. This means that it is a suspending function (think async/await) which can only be called inside a coroutine. This forces Flow.collect to be called inside a coroutine guaranteeing that Flows will have a well-defined scope.
While this seems like a small distinction, in the world of Android (an embedded system with limited memory resources) having better contracts for scoping async work leads directly to fewer memory leaks, improving performance and reducing risk of crashes. Now, with structured concurrency from Kotlin coroutines, we can use things like Jetpack's viewModelScope, which auto-cancels our running flow when the view model is cleared. This cleanly solves a core problem faced by all Android applications: how to determine when resources from background tasks are no longer needed.
public fun CoroutineScope.launch(...)
viewModelScope.launch {
flow.collect{ handle(it)
}
}
Structured concurrency was the biggest reason why we switched to Flow. Our next biggest reason to switch was to align ourselves with the direction of the broader Android community. We’ve already seen that AndroidX loves Kotlin and Coroutines. Many libraries like ViewModel already support coroutine scopes, Room has first-class Flow support. There is even talk of new libraries that are being converted to use coroutines as an async primitive (Paging). It was important to us to rewrite Store in a manner that aligns with the Android ecosytem, for not just today but many years to come.
Lastly, while we do not have current plans to use Store for anything but Android, we felt that the future may include Kotlin multi-platform as a target and wanted to have as few dependencies as possible. RxJava is not compatible with Kotlin native/js and pulls in 6,000+ functions).
What is a Store?
A Store is responsible for managing a particular data request. When you create an implementation of a Store, you provide it with a Fetcher which is a function that defines how data will be fetched over the network. Optionally, you declare how your Store will cache data in-memory and on-disk. Since Store returns your data as a Flow, threading is a breeze! Once a Store is built, it handles the logic around your data fetching/sharing/caching, allowing your views to use the most up-to-date data source and ensuring that data is always available for offline use.
Fully Configured Store
Let's start by looking at what a fully configured Store looks like. We will then walk through simpler examples showing each piece:
StoreBuilder.fromNonFlow { api.fetchSubreddit(it, "10")}
.persister(
reader = db.postDao()::loadPosts,
writer = db.postDao()::insertPosts,
delete = db.postDao()::clearFeed)
.cachePolicy(MemoryPolicy)
.build()The above builder is declaring:
- In-memory caching for rotation
- Disk caching for when users are offline
- Rich API to ask for data whether you want cached, new, or a stream of future data updates.
Store additionally leverages duplicate request throttling to prevent excessive calls to the network and allows the disk-cache to be used as a source of truth. The disk-cache implementation is passed through the persister() builder function and can be used to modify the disk directly without going through Store. Source of truth implementations work best with databases that can provide observable sources like Jetpack Room, SQLDelight, or Realm.
And now for the details:
Creating a Store You create a Store using a builder. The only requirement is to include a function that returns a Flow or a suspend function that returns a ReturnType.
val store = StoreBuilder.from {
articleId -> api.getArticle(articleId) //Flow<Article>
}
.build() Store uses generic keys as identifiers for data. A key can be any value object that properly implements toString(), equals() and hashCode(). It will be passed to your Fetcher function when it is called. Similarly, the key will be used as a primary identifier within caches. We highly recommend using built-in types that implement equals and hashcode or Kotlin data classes for complex keys.
Public Interface: Stream
The primary public API provided by a Store instance is the stream function which has the signature:
fun stream(request: StoreRequest<Key>): Flow<StoreResponse>Output>>Each stream call receives a StoreRequest object, which defines which key to fetch and which data sources to utilize. The response is a Flow of StoreResponse. StoreResponse is a Kotlin sealed class that can be either a Loading, Data, or Error instance. Each StoreResponse includes a ResponseOrigin field which specifies where the event is coming from.

- The Loading class only has an origin field. This can be a good signal to activate the loading spinner in your UI.
- The Data class has a value field which includes an instance of the type returned by Store.
- The Error class includes an error field that contain the exception thrown by the given origin.
When an error occurs, Store does not throw an exception, instead, it wraps it in a StoreResponse.Error type which allows Flow to not break the stream and still receive updates that might be triggered by either changes in your data source or subsequent fetch operations. This allows you to have truly reactive UIs where your render/updateUI function is a sink for your flow without ever having to restart the flow after an error is thrown. See example below:
lifecycleScope.launchWhenStarted {
store.stream(StoreRequest.cached(key = key, refresh=true)).collect { response ->
when(response) {
is StoreResponse.Loading -> showLoadingSpinner()
is StoreResponse.Data -> {
if (response.origin == ResponseOrigin.Fetcher) hideLoadingSpinner()
updateUI(response.value)
}
is StoreResponse.Error -> {
if (response.origin == ResponseOrigin.Fetcher) hideLoadingSpinner()
showError(response.error)
}
}
}
}For convenience, there are Store.get(key), Store.stream(key) and Store.fetch(key) extension functions.
- suspend fun Store.get(key: Key): Value
This method returns a single value for the given key. If available, it will be returned from the in-memory or disk cache - suspend fun Store.fresh(key: Key): Value
This method returns a single value for the given key that is obtained by querying the fetcher. - suspend fun Store.stream(key: Key): Flow
This method returns a Flow of the values for the given key.
Here’s an example using get() which is a single shot function:
lifecycleScope.launchWhenStarted {
val article = store.get(key)
updateUI(article)
}On a fresh install when you call store.get(key), the network response will be stored first in the disk-cache (if provided) and in an in-memory cache afterwards. All subsequent calls to store.get(key) with the same key will retrieve the cached version of the data, minimizing unnecessary data calls. This prevents your app from fetching fresh data over the network (or from another external data source) in situations when doing so would unnecessarily waste bandwidth and battery. A great use case is any time your views are recreated after a rotation, they will be able to request the cached data from your Store. Having this data always available within a Store will help you avoid the need to retain copies of large objects in the view layer. With Store, your UI only needs to retain identifiers to use as keys while declaring whether it is ok to return the first value from cache or not.
Busting through the cache
Alternatively you can call store.fetch(key) to get a suspended result that skips the memory (and optional disk cache). A good use case is overnight background updates which use fetch() to make sure that calls to store.get()/stream() will not have to hit the network during normal usage. Another good use case for fetch() is when a user wants to pull to refresh. Calls to both fetch() and get() emit one value or throw an error.
Stream
For real-time updates, you may also call store.stream(key) which creates a Flow that emits each time the disk-cache emits or when there are loading/error events from network. You can think of stream() as a way to create reactive streams that update when your db or memory cache updates.
lifecycleScope.launchWhenStarted {
store.stream(StoreRequest.cached(3, refresh = false))
.collect{ }
store.stream(StoreRequest.get(3)) //skip cache, go directly to fetcher
.collect{ }
Inflight multicasting
To prevent duplicate requests for the same data, Store has a built-in inflight debouncer. If a call is made that is identical to a previous request that has yet to complete, the same response for the original request will be returned. This is useful for situations when your app needs to make many async calls for the same data at startup or when users are obsessively pulling to refresh. As an example, you can asynchronously call Store.get() from 12 different places on startup. The first call blocks while all others wait for the data to arrive. We saw a dramatic decrease in data usage after implementing this inflight logic in NYT.
Disk as cache
Store can enable disk caching by passing an implementation to the persister() function of the builder. Whenever a new network request is made, the Store will first write to the disk cache and then read from the disk cache to emit the value.
Disk as single source of truth
Providing a persister whose read function can return a Flow allows you to make Store treat your disk as the source of truth. Any changes made on disk, even if it is not made by Store, will update the active Store streams. This feature, combined with persistence libraries that provide observable queries (Jetpack Room, SQLDelight, or Realm) allows you to create offline first applications that can be used without an active network connection while still providing a great user experience.
StoreBuilder.fromNonFlow {api.fetchSubreddit(it, "10")}
.persister(
reader = db.postDao()::loadPosts,
writer = db.postDao()::insertPosts,
delete = db.postDao()::clearFeed)
.cachePolicy(MemoryPolicy)
.build()Stores don’t care how you’re storing or retrieving your data from disk. As a result, you can use Stores with object storage or any database (Realm, SQLite, Firebase, etc). If using SQLite we recommend working with Room developed by our friends on the Jetpack team.
The above builder and Store stream API is our recommendation for how modern apps should be working with data. A fully configured store will give you the following capabilities:
- Memory caching with TTL and Size policies
- Disk caching including simple integration with Room
- Multicasting of responses to identical requestors
- Ability to get cached data or bust through your caches (
StoreRequest) - Ability to listen for any new emissions from network (stream)
- Structured concurrency through APIs build on
Coroutinesand KotlinFlow
Wrapping Up
We hope you enjoyed learning about Store. We can't wait to hear about all the wonderful things the Android community will build with it and welcome any and all feedback. If you want to be even more involved, we are currently hiring all levels of mobile engineers in our NY, SF, and SEA offices. Come help us continue build great products both for our users and the developer community.
This information was presented at KotlinConf, if you would rather watch a presentation.
You can find the Store library here: github.com/dropbox/Store
Portions of this page are modifications based on work created and shared by the Android Open Source Project and used according to terms described in the Creative Commons 2.5 Attribution License .


